广州云徙科技
JSP和Servlet的区别
- jsp经编译后就变成了Servlet.(JSP的本质就是Servlet,JVM只能识别java的类,不能识别JSP的代码,Web容器将JSP的代码编译成JVM能够识别的java类)
- jsp更擅长表现于页面显示,servlet更擅长于逻辑控制.
- Servlet中没有内置对象,Jsp中的内置对象都是必须通过HttpServletRequest对象,HttpServletResponse对象以及HttpServlet对象得到.
- Jsp是Servlet的一种简化,使用Jsp只需要完成程序员需要输出到客户端的内容,Jsp中的Java脚本如何镶嵌到一个类中,由Jsp容器完成。而Servlet则是个完整的Java类,这个类的Service方法用于生成对客户端的响应。
软件工程常见开发模型
| 模型 | 核心思想 | 关键特点 | 主要适用场景 | 主要弱点/挑战 |
|---|---|---|---|---|
| 瀑布模型 | 线性顺序,阶段固化 | 结构化、文档化、风险后置 | 需求稳定清晰、技术成熟、文档严格 | 抗拒变更、风险后置 |
| 增量模型 | 功能分批构建交付 | 模块化、分批次交付、降低整体风险 | 需求可分优先级、可分期交付大型系统 | 增量间接口、整体架构需早期设计 |
| 迭代模型 | 循环活动,逐步求精 | 灵活、适应性强、快速反馈、风险前移 | 需求不明确/易变、高风险、大型复杂、需反馈 | 依赖有效沟通、持续用户参与 |
| 螺旋模型 | 风险驱动的迭代循环 | 风险驱动、高度灵活、融合多种方法 | 大型复杂高风险项目、重大变革、安全关键系统 | 复杂、成本高、依赖风险管理能力 |
| 喷泉模型 | 阶段重叠无缝回溯(面向对象) | 无缝回溯、阶段交织、自然映射对象生命周期 | 面向对象开发、快速原型、组件复用 | 管理难度大、实践应用较少 |
插入排序
插入排序就像斗地主排牌,先找到一张比前边小的,这个肯定要放在我这个位置之前,至于放在哪,应该在进行一轮循环比较
public void insertionSort(int[] arr) { for (int i = 1; i < arr.length; i++) { int val = arr[i]; int j = i; while (j > 0 && arr[j - 1] > val) { arr[j] = arr[j - 1]; j--; } arr[j] = val; } }
深圳小赢科技
Drools->restful->MVC completableFuture->基础线程使用 不懂的东西别多嘴
为什么要使用Drools(Rete算法)
常用API调用链
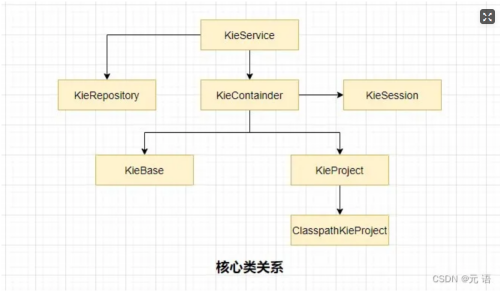
工作流程
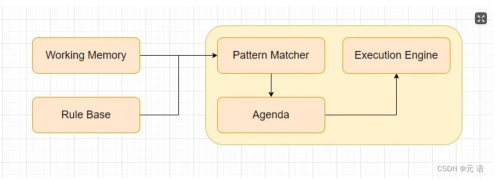
Drools的优势
- 在不改变原有代码的情况下修改规则(动态性和灵活性)
- 业务规则和应用程序代码解耦
- 集中化管理和复用
- 基于这个规则网络在特定场景下(增量匹配,规则网络优化)性能会更好,对于一些简单的规则,if-else会更快些
缺点
RETE算法使用了存储区存储已计算的中间结果,以空间换取时间,从而加快系统的速度。然而存储区根据规则的条件于事实的数目成指数级增长,极端情况下会耗尽系统资源。
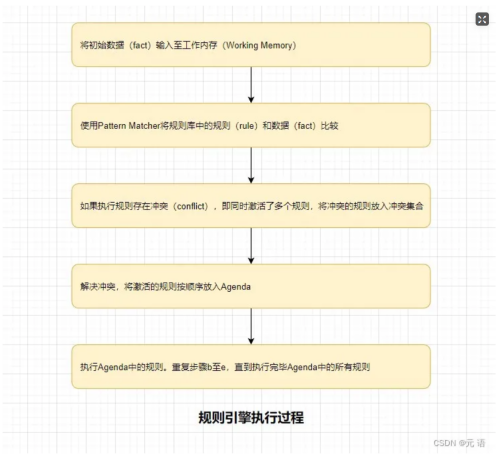
Rete算法
背景
规则引擎的核心任务是高效地匹配规则中的条件与输入数据(事实),并执行相应的动作。 然而,随着规则数量和数据规模的增加,简单的线性匹配方法会导致性能瓶颈。Rete算法通过构建一个高效的模式匹配网络(Rete网络),显著提高了规则匹配的效率。
核心结构
Rete网络:
- Alpha网络:对单一事实进行过滤,每个Alpha节点对应规则中的一个条件,当一个事实键入网络时,沿着Alpha网络传播,通过一系列条件过滤之后,会进入Alpha存储器,用于存储过滤的事实。
- Beta网络:Beta网络用于匹配多个事实,处理规则中涉及多个条件的逻辑关系,Beta网络由Beta节点组成,用于匹配多个事实之间的关系,Beta网络的末端是Beta存储器,用于存储部分匹配的结果。

两个线程循环打印1-100,加锁有必要吗,死锁怎么办
互斥性是要保证的,但是不一定要加锁,对于公共变量的操作,如果不加锁,不能保证相应的执行顺序,不单单可以使用sychorized,也可以使用互斥量,或者是原子类。
加锁实现
“
public class OneToHundred {
private static Object lock = new Object();
private static int count = 0;
private static final int limit = 100;
public static void main(String[] args) {
new Thread(() -> {
while (true) {
synchronized (lock) {
if (count <= limit) {
if (count % 2 == 1) {
System.out.println(count);
count++;
lock.notifyAll();
} else {
try {
lock.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
}
}).start();
new Thread(() -> {
while (true) {
synchronized (lock) {
if (count <= limit) {
if (count % 2 == 0) {
System.out.println(count);
count++;
lock.notifyAll();
} else {
try {
lock.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
}
}).start();
}
}
信号量实现
“
public class PrintNumbersSemphore {
private static int count = 1;
private static int max = 100;
private static Semaphore oddSemaphore = new Semaphore(1);
private static Semaphore evenSemaphore = new Semaphore(0);
public static void main(String[] args) {
Thread oddThread = new Thread(() -> {
while (count < max) {
try {
oddSemaphore.acquire();
System.out.println("Odd: " + count);
count++;
evenSemaphore.release();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
Thread evenThread = new Thread(() -> {
while (count < max) {
try {
evenSemaphore.acquire();
System.out.println("Even: " + count);
count++;
oddSemaphore.release();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
evenThread.start();
oddThread.start();
}
}
基于原子类实现
public class AutomicPrintNumbers {
private static AtomicInteger counter=new AtomicInteger(1);
private static AtomicInteger turn=new AtomicInteger(0);
public static void main(String[] args) {
Thread a=new Thread(new PrintNumbers(0));
Thread b=new Thread(new PrintNumbers(1));
a.start();
b.start();
}
static class PrintNumbers implements Runnable{
private int threadId;
public PrintNumbers(int threadId) {
this.threadId = threadId;
}
@Override
public void run() {
while (counter.get()<=100){
while (turn.get()==threadId){
// 双重检查防止被唤醒后已超过100
if (counter.get() > 100) {
break;
}
System.out.println(Thread.currentThread().getName() + ": " + counter.getAndIncrement());
// 切换执行权
turn.set(1 - threadId);
// 主动让出CPU防止忙等待
Thread.yield();
}
}
}
}
}
覆盖索引(这个没啥问题)
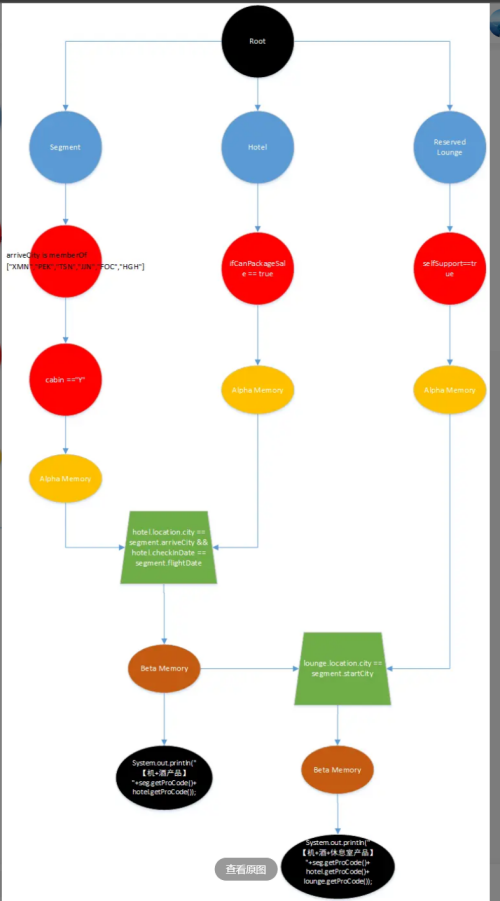
MVC的请求流程
用户请求->前端解析器(DisparthServlet)->HandlerMapping(处理器映射),返回给DisparthServlet处理器链->Ds然后请求处理器适配器->适配器请求自己的controller,返回modelAndView->DS将mV返回给视图解析器->视图解析器返回View给DS->渲染视图,返回响应
对于校验接口的优化,除了并行化之外,还有没有优化方案,为什么这个接口会这么慢
- 为什么这么慢性能瓶颈在这个resourceSelect的checkData的方法中校验环节:资源唯一性校验,流程唯一性校验,特殊校验,这些校验都要查全表,不仅需要大量的数据库连接,并且有大量的I/O操作,涉及到一些表的索引的问题,还有一些数据的序列化操作,数据的获取,处理,校验都是比较耗时的工作
- 除了并行化,还可以怎么优化对相应的表优化索引,对一些经常使用的,变更不频繁的数据可以使用ES进行缓存,每次查询的话先查询ES,直接用ES中的数据进行校验 Drools会话的优化,使用会话池 或者一些数据的分批入库
知衣科技
Drools
分布式事务
分布式事务的方案
2PC
引入一个事务协调者来管理整个事务的执行过程,但是会存在单点故障(协调者是单点的),数据不一致(各个服务之间通过网络交互,网络会出现问题),同步阻塞(在执行事务的时候可能会影响应用对相应资源的操作)
数据库根据2pc协议进行了相应改造,对于一个事务修改的记录,通过记录日志的操作保证故障恢复解决单点故障问题,通过单独移除自身业务记录锁实现提交的原子性,解决数据不一致的问题,对于其他相应被影响的记录,在访问时会被路由到初始数据更改处,如果这个初始数据已经被提交,则确定可以访问。
3PC
比2PC多了一个预准备阶段,这个阶段会检查有没有哪些节点有故障,在三阶段进行提交或回滚时可以不依赖事务管理者
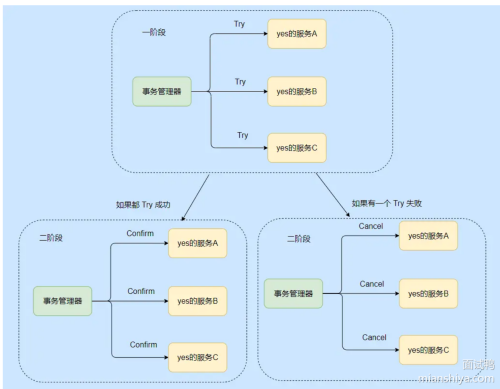
TCC
TCC则是在业务层面进行事务的构造,一般有这个Try,Confirm,Cancel阶段,try的话就是检查事务需要的资源,在Confirm阶段执行真正的操作
XA规范
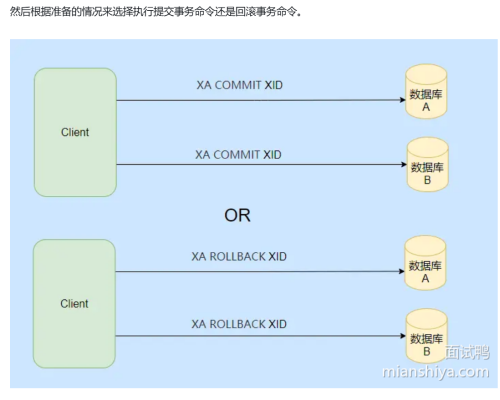
本地消息表
事务消息
spring事务传播机制,什么情况下使用requires_new
required
有事务则加入当前事务,没有事务则创建一个事务 适用于需要进行事务操作的的场景,比如订单时调用库存减少的方法
requires_new
新建一个新事务,如果存在当前事务则挂起
适用于日志记录,通知服务,即使主事务失败,也不影响独立的事务操作
supports
支持当前事务,如果不存在以非事务方式执行
适用场景某个方法可以在事务的内部或外部执行
not_supported
不支持当前事务,始终以非事务方式执行
适用于读取配置信息,不需要事务控制的数据获取操作
never
不支持当前事务,如果存在事务,则抛出异常
适用于需要保证绝对没有事务的场景
mandatory
支持当前事务,如果不存在则抛出异常
适用于必须在现有事务中执行的场景
nested
有事务则嵌套执行,内层事务不影响外层,外层失败内部也会回滚
适用于需要部分回滚或者局部事务的场景
JAVA锁(AQS)
单例模式(Sychorinzed)在什么情况下sychorinzed必须使用
“
package org.example;
public class Singleton {
//饿汉模式
private static Singleton instance = new Singleton();
class Singleton1 {
//懒汉
private static Singleton instance;
public static Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}
class Singleton2 {
//双重校验锁
private static volatile Singleton instance;
public static Singleton getInstance() {
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
return instance;
}
}
class Singleton3 {
//静态内部类
private static class SingletonHolder {
private static final Singleton instance = new Singleton();
}
public static Singleton getInstance() {
return SingletonHolder.instance;
}
}
class Singleton4 {
//枚举
public enum Singleton45 {
INSTANCE;
public void doSomething() {
//do something
}
}
}
}
为什么要使用CompletableFuture
- 灵活的组合编排
- 精细的异常处理
- 非阻塞异步执行
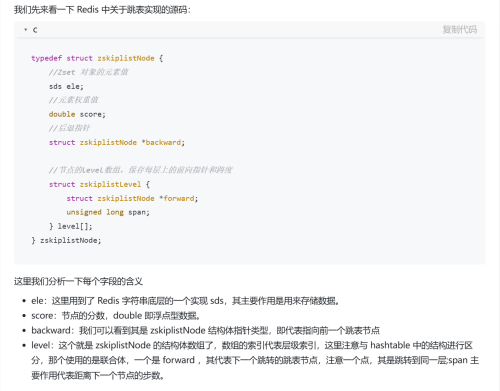
ZSet跳表
ZSet是Redis中的一个特殊的数据结构,他的核心其实是一个多层链表
查找:会从高层查到底层,基于zset特殊的数据结构,一般情况下比普通链表可以少遍历几个元素
删除:因为这个前驱指针的设计,删除也比较方便
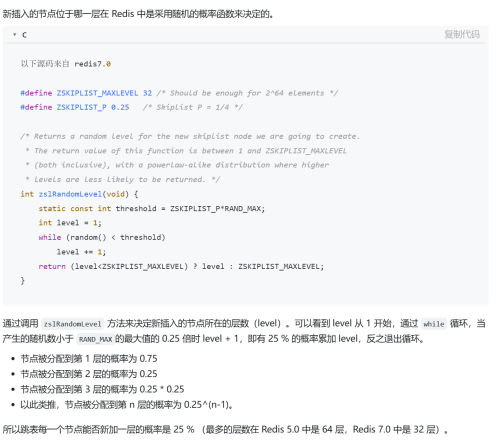
新增:基于概率算法,计算这个新节点在哪一层
如何判断一个大模型的能力
核心能力:任务目标的达成度
预测模型:一些预测的误差
分类任务:准确率,召回率,精确率,F1分数
生成任务:人工评估
泛化能力:对未知数据的适应性
模型在训练集之外的真实数据上的表现,泛化能力不足的模型可能过拟合或欠拟合
验证方法:划分数据集,交叉验证
鲁棒性:对干扰的稳定性
在非理想输入情况或环境变化下的可靠性
噪声鲁棒性,数据偏移
就主要通过扰动数据来检验模型的鲁棒性吧,对抗训练
可解释性:决策逻辑的可理解性
全局可解释性,局部可解释性,或者借助可视化工具
效率:资源与时间的损耗
训练效率,推理效率
适应性:对新任务的快速适配
迁移学习能力/零样本学习能力
可靠性:稳定运行的能力
模型在实际部署中需要具备的持续稳定输出
招银网络科技
为什么使用B+树而不使用hash或者B树
B+树的优点
- 支持范围查询,因为叶子节点双向链表的巧妙设计。
- 支持排序操作,B+树叶子节点按照关键字顺序存储,可以快速支持排序操作,提高排序效率。
- 存储更多的索引数据。
- 节点分裂和合并时,IO操作少,叶子节点大小固定为一页
- 有利于磁盘预读,结合cpu的特性,可以减少IO操作次数
- 有利于缓存,还是基于这个非叶子节点只存储索引的这个结构,可以在缓存中存储更多的索引数据。
为什么不使用红黑树或者B树
范围查询,磁盘预读,优化排序这些红黑树和B树统统做不到
B+树和Hash索引的区别
hash不适合范围查询和排序操作,维护成本较低,但存储无序,查询效率会降低。
接口和抽象类的区别
方法定义:接口不能直接实现逻辑,抽象类是可以实现逻辑的,抽象类更像模板方法
修饰符:接口默认public
构造器:抽象类可以有构造器,接口不能有构造器
单继承多实现:一个类只能被集成一次,而一个类可以实现多个接口
orrivde注解重写失效
- 访问权限不匹配:子类的访问权限大于了父类权限
- 方法签名不一致:参数列表不同
- 返回类型不匹配:返回类型不同也会失效
- 重写方法抛出新的异常:子类抛出了更大范围的受检异常
- 重写了构造方法:子类是基于父类的构造方法构造的,所以重写构造方法会失效
RR视图和RC视图生成的区别
都是快照读,只是RR对于每个事务创建时只生成一次视图,而RC是对于每个读操作都生成一次视图
线程池参数设置(根据亚信科技的场景)
300QPS
- 核心线程数:基于IO密集的业务场景,设置在8(cpu核心数*(1+平均IO等待时间/CPU计算时间))
- 最大线程数:考虑到内存溢出的问题和上下文切换开销,设置为16(corePoolSize*2~4);
- 任务队列:使用固定容量的有界队列(20) 队列容量(最大QPS-corePoolSize*每秒处理能力) *平均处理时间
- 拒绝策略:进行异常抛出捕获,记录日志,本地消息表,定时任务补偿
补偿机制
本地消息表,消息队列
红黑树左旋右旋
三次旋转内解决
大华
网络抓包和Unix
网络抓包的核心价值
调试接口,定位接口异常(如参数错误,状态码非200)
排查网络问题:分析延迟,丢包,重传
安全检测:发现恶意流量(DDos攻击,SQL注入,UDP包丢失)
协议学习:观察真实网络中协议的交互过程(DNS解析,TLS握手)
具体场景
调试API接口
选择Charles 配置抓包环境(证书)->启动抓包绑定ip过滤规则->分析请求与响应
排查请求超时(HTTP问题)
使用WireShark 绑定ip和端口->登录网站->分析关键事件(DNS解析慢,数据传输延迟,重传与丢包)
检查恶意流量
WireShark捕获群入栈流量->分析攻击特征(ICMP流,SYN流多个SYN却没有ACK,UDP流大量无意义UDP包)->关联攻击源(通过WireShark的Statistics->Endpoints统计源IP流量),结合防火墙日志,确认IP是否被封禁。
优化移动端APP网络性能
Charles和WireShark结合使用 Charles模拟弱网环境,运行WireShark抓包分析
虾皮
十亿不同数字,分成十组,每组一亿个,每次分组都不同
随机排列+动态种子
使用一个随机种子对索引列随机排序,用重新排序后的索引列重排原数组,然后切分
Hash加盐算法
若内存无法容纳全量数据的随机排列,可采用哈希函数分配,通过改变哈希参数(如“加盐”)确保每次分组不同。
步骤:
a. 为本次分组选择一个新的哈希函数 H k (x)(如 H k (x)=SHA-256(x∥k),其中 k为本次分组的唯一密钥)。
b. 对每个数字 x∈S,计算其哈希值 h=H k (x),并将 h转换为0-9的整数 g(如取哈希值的最后一位十进制数,或对10取模)。
c. 由于十亿是10的倍数,均匀哈希函数可保证每个组 g∈{0,1,…,9}恰好包含一亿个数字。
一个订单表,有user_id,order_time,price,写一个sql查询,这个日期之前价格的汇总
-- 按日期展示累计价格总和(含当日) SELECT DATE(order_time) AS time, -- 提取日期(格式:YYYY-MM-DD) SUM(price) OVER ( ORDER BY DATE(order_time) -- 按日期排序 ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW -- 累计从首行到当前行 ) AS price_sum -- 累计价格总和 FROM orders GROUP BY DATE(order_time) -- 按日期分组(确保每个日期仅一行) ORDER BY time; -- 按日期升序排列
编译好的代码是怎么在cpu执行的
编译阶段
预处理(预处理后的源代码)->编译(由高级语言将源代码编译为汇编语言)->汇编(将汇编语言转换为机器码)->链接(将多个目标文件和依赖的库文件合并,为指令和数据分配运行内存地址,生成可执行文件exe或者ELF文件)
加载阶段(从磁盘到内存)
- 创建进程:操作系统为程序分配虚拟地址空间,创建PCB
- 内存映射:为创建的虚拟内存映射实际的物理内存
- 入口点跳转:将CPU的程序计数器设置为可执行文件的入口
指令周期
取值(通过程序计数器记录下一条要执行的指令)->译码(根据指令解析出操作码和操作数,生成信号)->执行(通过算数逻辑单元和内存访问单元以及总线进行交互)->写回(将结果协会寄存器或者内存开启下一个周期)
CPU优化技术
- 流水线:当地一条指令执行的时候,第二条指令在译码,理想情况下,CPU可以每周期执行一个指令。
- 分支预测:对于条件跳转会进行预测,提前加载可能的目标指令到流水线,预测正确可以复用流水线,否则就要回滚。
- 超标量执行:多执行单元(多ALU,多内存访问),指令并行,同时处理多个指令
- 缓存:CPU内部三级告诉缓存
社交软件的redis存储(用户信息,session)如何设计
数据结构
Hash或者String
String适合简单场景,用户属性较少
Hash适合复杂场景,如果需要频繁修改Session中的某个字段,使用hash更高效
缓存一致性
- 延迟双删策略:适合于并发系统,为了防止更新缓存后旧请求将新缓存错误更新,所以会在更新完缓存之后过一段时间再进行删除。
- 写穿透(Write-Through) 通过缓存代理处理写请求,先更新缓存再同步更新数据库(对一致性要求高但性能要求较低的场景)
- 写回(Write-Behind) 写请求仅更新缓存,然后异步更新数据库,对写入性能要求极高,但允许短暂数据不一致(如日志统计)
- 旁路缓存:读的时候优先读缓存,写的时候先写数据库然后让缓存失效对于高频读,低频写的社交业务场景,可以采用旁路缓存+延迟双删的策略
过期机制
删除策略:选择定期和惰性删除这块,定期用来防止内存碎片,惰性用来防止读到过期的数据
过期时间设置:用户一些基本信息可以设置较长的TTL,session设置较短的TTL,动态内容可以设置为几小时或几天,结合热弟啊数据延长TTL,短信验证码则设置极短的缓存时间
一些优化策略:
- 动态调整TTL,结合用户活跃度,数据更新频率,动态延长或缩短TTL,平衡性能与内存
- 分散过期时间:通过随机设置过期时间,降低数据库缓存压力
- 分布式场景优化:集群架构或者主从延迟,集群分片,分布式锁配合这块
分布式场景下的挑战
- 主从架构下主从同步的过期延迟:主节点删除键后,从节点未同步,导致从节点读取到但未删除的键,可以采取优先读主节点,或者使用哨兵机制,主节点宕机时自动提升从节点为主节点,减少同步延迟对业务的影响。
- Redis集群过期处理:某个节点宕机,其他集群接管其槽位时的过期键遗漏问题,可以通过合理规划分片(如高频数据分散到不同节点,避免单节点故障导致大量过期键未清理),并购使用监控机制(Prometheus+Grafana)监控个节点的过期键指标
- 分布式锁注意锁续期
常见问题的排查
缓存未按时过期
通过TTL命令或者检查Redis日志,确认是否有主从同步延迟或者未设置过期时间,或者时钟异常 过期键未清理
使用hz参数,增加定期删除频率,可能是因为定期删除的扫描比率低,监控expired_stale_perc的比例,如果长期高于20%,可以优化TTL配置
缓存和数据库的一致性如何保证,在这个社交软件的场景下
- 延迟双删策略:适合于并发系统,为了防止更新缓存后旧请求将新缓存错误更新,所以会在更新完缓存之后过一段时间再进行删除。
- 写穿透(Write-Through) 通过缓存代理处理写请求,先更新缓存再同步更新数据库(对一致性要求高但性能要求较低的场景)
- 写回(Write-Behind) 写请求仅更新缓存,然后异步更新数据库,对写入性能要求极高,但允许短暂数据不一致(如日志统计)
- 旁路缓存:读的时候优先读缓存,写的时候先写数据库然后让缓存失效对于高频读,低频写的社交业务场景,可以采用旁路缓存+延迟双删的策略
如何定位一个方法函数的性能瓶颈
量化指标->定位热点->分析原因->验证优化
明确性能问题
根据抛错明确性能的表现
量化性能指标
代码层面:使用代码打印日志明确方法耗时
外部计时工具:linux系统自带time指令,APM工具(SkyWalking,Zipkin,Pinpoint)埋点自动插桩,可视化幻术调用链的耗时分布。
定位性能热点
选择profiler工具,如VisualVM,火焰图分析
关注CPU占用,调用次数,内存分配,IO等待,锁竞争
分析瓶颈类型
CPU密集型 低效算法(算法时间复杂度较高) 内存密集型 内存泄漏,不合理的缓存策略 IO密集型 数据库查询慢,网络请求延迟 并发瓶颈 锁竞争,线程池配置不合理,资源争用
优化验证
测试环境验证,JMeter压测,APM工具
如何确保一个函数是线程安全的
线程安全
多线程并发访问共享资源竞争导致数据不一致或不可预期行为。
线程不安全的原因
多个线程对共享资源非原子操作
确保线程安全常见方法
互斥锁:确保同一时间只有一个线程能访问共享资源
读写锁:适合读多写少的场景
原子操作:CAS
线程本地存储:ThreadLocal
不可变状态:单例模式
还有可见性保证 volatile
加餐:分布式系统下时间不同步问题
原因
- 硬件时钟(RTC)和系统时钟差异:系统时钟是从硬件时钟中读取数据,但是晶振有误差,会导致系统时钟与真是时间偏差。
- NTP网络协议服务配置出错:NTP服务器被防火墙连接,网络延迟出错。
- 时钟漂移:硬件层面晶振误差无法避免。
- 虚拟化与容器环境的时间问题:虚拟机依靠hypervisor,同步失败,时间会漂移,另外容器默认共享宿主机时间,但容器进程银时区配置错误会导致时间偏差。
解决方案
- 常规场景:配置NTP服务 高精度场景:结合PTP(精确时间协议),需要配备支持PTP的网卡
- 容器与虚拟机环境时间同步,采用hypervisor时间同步
- 定期校准与监控:使用ntpd-p(NTP服务状态)和date-u(时间偏移)指令,或者部署Prometheus监控
- 以上都不行进行人工同步
招银二面
增量对账中的删除记录,消息队列保证缓存一致性的这块增量对账是如何做的
对于增量对账更新,对于插入,更新,删除这样的变更操作提供对账操作
对账触发条件
定时触发:每五分钟触发一次
事件堆积触发:对于任意操作类型事件堆积量超过阈值(一万条),提前触发对账
对账数据范围
时间窗口:基于事件时间戳,但核对最近5分钟内的事件
事件溯源:通过binlong_file和binlog_pos从Canal或Mysql拉取原始事件,确保对账范围准确
全操作对账逻辑
从MysqlBinlog中按五分钟的窗口阈值,每五分钟捕获变更操作,然后与ES中的操作记录比对
插入操作
正向对账
从Mysql Binlog提取最近五分钟的INSERT事件M_insert(主键,after字段)
从ES查询M_insert所有主键对应的文档是否存在
不存在标记未“ES未插入”
存在查看after字段是否一致
反向对账
从ES提取最近五分钟新增的文档集合E_insert
从MySQL查询E_insert中所有主键对应的记录是否存在且未删除:
若不存在或删除:标记“Mysql未插入”
更新操作
正向对账
从BinLog提取最近的M_update(before/after字段,changed_fields)
从ES查询M_update中所有主键对应的文档
不存在标记为“ES未插入”
存在:检验changed_fields对应的ES字段是否与after字段一致
反向对账
从ES提取最近五分钟有更新的文档集合E_update(通过ES的update_time字段)
从MySQL查询E_update中的所有主键记录对应的记录的update_time
如果MySQL更新时间晚,标记为“ES未同步最新更新”(不一致)
删除操作
正向对账
拉取近五分钟内所有DELETE时间,得到集合
从ES查询主键对应的记录是否存在
若存在,标记为“ES未删除”
反向对账
从ES中提取最近五分钟有变更的数据,得到集合E
从MySQL中查询这些记录是否已被删除
查询delete_time字段,如果Mysql中无数据(删除时间字段不为空),标记为“Mysql未删除”
差异修复策略
| 不一致类型 | 修复策略 |
|---|---|
| ES未插入(新增不一致) | 重新发送对应INSERT事件到RocketMQ,或直接调用ES indexAPI插入文档。 |
| ES字段不一致(更新不一致) | 提取MySQL after字段与ES当前字段的差异,调用ES updateAPI同步更新。 |
| ES未删除(删除不一致) | 重新发送对应DELETE事件到RocketMQ,或直接调用ES deleteAPI删除文档。 |
| MySQL未插入(反向新增不一致) | 检查是否为ES误插(如主键冲突),删除ES文档;若是MySQL插入失败,同步MySQL正确数据。 |
| ES未同步最新更新(反向更新不一致) | 从MySQL拉取最新after字段,调用ES updateAPI覆盖ES文档。 |
表索引优化这块,具体的优化流程和细节,建了多少条索引
如何获取信息
SELECT INDEX_NAME, COLUMN_NAME, SEQ_IN_INDEX, INDEX_TYPE, CARDINALITY, *-- 索引基数(选择性关键指标)* INDEX_COMMENT FROM INFORMATION_SCHEMA.STATISTICS WHERE TABLE_SCHEMA = 'your_db' AND TABLE_NAME = 'address';
使用以上sql可以查看具体address表的索引列
分析索引低效问题
- 冗余索引:索引A的列是冗余索引的前缀
- 低选择性索引:索引技术远小于表总行数
- 长索引列:索引不包含长字符串列,导致索引体积大,IO开销高
- 未覆盖查询的索引:高频查询所需要的列未被现有索引覆盖,需要回表查询
定位高频慢查询
启用码查询日志,或者数据库监控工具,Percona Toolkit等等
索引的删除策略
识别冗余索引,在索引低效板块已经提到
安全删除冗余索引
可以使用Explain语句确认冗余索引是否被实际查询使用
索引设计重建
确定高频查询的覆盖需求
最左前缀匹配,包含返回列,控制索引长度
索引重建实践
尽量选择离线重建,对于一些紧急场景可以是哦那个inplace算法避免长时间锁表
对于索引长度超过数据长度场景避免的解决方案
索引条数设置原则
最小化索引列数:仅保留高频查询
控制单列长度:对字符串列使用前缀索引,减少索引占用空间
优化符合索引顺序:按照技术递减排序,基数高的列在前,提升索引选择性
平衡读写开销:索引越多,写操作的开销越大,需权衡读写性能
索引的缺陷
索引对写入性能的影响
写入延迟增加:插入数据时需要同步更新索引 锁竞争加剧:索引更新需要加写锁,高并发场景下导致锁等待,甚至死锁
索引选择性的限制
低选择性列索引失效,符合索引顺序错误
索引存储开销
长字段索引占用空间大,复合索引空间膨胀
分布式场景下的索引挑战
在分库分表,主从复制或分布式数据库中,索引的维护和使用面临额外挑战
具体表现:跨库索引失效,主从复制延迟增加,分布式事务影响,索引更新需要跨节点协调,导致事务提交事件变长。
索引维护的复杂性
- 重建索引锁表
- 冗余索引堆积
- 统计信息过时:索引统计信息未及时更新导致优化器选择错误的索引
明源云
canal服务失效断开怎么办,恢复后怎么实现崩溃恢复
分析失效原因
- 服务宕机:Canal进程崩溃(OOM,硬件故障)。
- 网络中断:Canal与MySQL的Binlog事件无法发送到RocketMQ,消费者无法同步更新缓存,导致缓存与数据库数据不一致。
- MySQL主从异常:主从复制延迟或者中断,导致Canal无法获取Binlog
- 配置错误
Canal失效的实时监控与检测
分别监控
Canal服务状态,Mysql连接状态,Binlog读取进度,RocketMQ发送状态
告警规则
一级告警(紧急):Canal进程宕机,Mysql连接中断
二级告警(预警):Binlog读取进度停滞(5分钟内无新事件),RockerMQ发送成功率<90%
临时补救机制
- 切换备用Canal实例(但是从节点需要同步读取进度)
- 记录失效时间的BInlog偏移量(在Canal的元数据存储中持久化最后读取Binlog的位置)
- 临时启用Mysql直接同步(利用Mysql的binlog_dump工具直接读取Binlog,将事件发送到RocketMQ)
崩溃恢复方案
验证状态
查看进程是否正常运行,与Mysql连接是否正常
追赶失效期间的Binlog事件
Canal恢复后,从最后记录的Binlog位置开始,重新读取并发送失效期间的Binlog事件到RocketMQ
追赶期间需要考虑消息的幂等性
以及之后的对账补偿机制等等
加餐 分库分表
考虑因素
- 数据分布均匀性
- 查询性能
- 写入吞吐量
- 扩容灵活性
- 高可用性
核心目标
- 水平扩展:将单库单表的压力分散到多个库表,支持千万级数据量下的高并发读写
- 降低单库复杂度:垂直分库拆分不同业务,水平分表拆分单表数据量(单表建议在1000万行~5000万行)
- 保证一致性:通过分布式事务、全局唯一ID、主从复制等技术,确保分库分表后数据一致
策略设计
垂直分库
将业务按功能模块拆分为独立数据库,降低单库的耦合度和维护成本。
水平分表
在垂直分库的基础上,对单表数据按分片键水平拆分为多张表,确保单表数据量可控
分片键的选择
- 高离散性:数据分布均匀,避免热点数据
- 强关联性:与业务查询强相关,减少跨分片查询
- 稳定性:值一旦生成不可修改(如UUID,雪花算法ID),避免数据迁移
分片算法
哈希取模:直接取模确定分片位置
范围分片:按分片键的范围划分分片
一致性Hash:通过一致性hash算法将分片键映射到哈希环,扩容时仅需迁移少量数据(适合需要弹性扩缩容的场景)
全局唯一ID生成(关键)
常见方案
| 方案 | 原理 | 优点 | 缺点 |
|---|---|---|---|
| 雪花算法(Snowflake) | 基于时间戳+机器ID+序列号生成64位ID(如:1位符号位+41位时间戳+10位机器ID+12位序列号)。 | 高性能、有序、全局唯一 | 依赖机器时钟(时钟回拨可能导致重复) |
| 数据库号段模式 | 数据库预分配ID段(如每次分配1000个ID),服务端本地使用完再申请新段。 | 有序、依赖数据库但复杂度低 | 扩容时需调整号段分配规则 |
| Redis自增 | 利用Redis的INCR命令生成全局自增ID(可结合时间戳防重复)。 | 高并发、有序 | 依赖Redis可用性 |
推荐方案
- 机器ID分配:雪花算法+机器动态分配机器ID
- 容灾设计:服务端缓存多个机器ID,避免单点故障
数据一致性与事务保障
| Seata AT模式 | 自动补偿事务(通过回滚日志实现)。 | 强一致性、短事务(如订单支付) |
|---|---|---|
| Seata TCC模式 | 手动定义Try/Confirm/Cancel接口,灵活控制事务边界。 | 长事务、资源需预留(如库存扣减) |
| 本地消息表 | 业务库中增加消息表,通过定时任务同步消息到其他库。 | 异步场景(如通知类操作) |
| 维度 | AT 模式 | TCC 模式 |
|---|---|---|
| 实现原理 | 自动补偿(基于 SQL 拦截 + undo_log) | 手动补偿(Try-Confirm-Cancel 三阶段) |
| 侵入性 | 低(仅需配置数据源代理) | 高(需编写三个阶段业务代码) |
| 适用场景 | 短事务、SQL 主导的业务(如下单、支付) | 长事务、复杂逻辑(如分期、跨系统协作) |
| 一致性级别 | 最终一致性(回滚同步,提交异步) | 强一致性(阶段内)或最终一致性 |
| 开发成本 | 低(业务无感知) | 高(需实现三阶段逻辑,保证幂等) |
| 性能 | 高(接近本地事务) | 中(需多次 RPC 协调) |
选择建议:
- 若业务以 SQL 操作为主、事务较短且追求低侵入性,优先选 AT 模式。
- 若业务逻辑复杂(如涉及外部接口调用)、事务较长或需要自定义补偿逻辑,优先选 TCC 模式。
科大讯飞
Spring Bean生命周期
- bean定义加载
- 实例化
- 初始化
- 属性填充/依赖注入(一些依赖注入和AWare接口)
- BeanPostProcessor前置处理
- 一些初始化方法(InitializingBean的实现还有一些自定义init-method方法)
- BeanPostProcessor后置处理(AOP的代理创建)
- Bean就绪可以使用(非常重要,不需要等到销毁函数的注册)
- 销毁阶段(实现DisposableBean接口或者自定义destory-method方法)
覆盖索引的缺陷
其实和索引缺陷如出一辙
- 写入性能,后续的索引维护上开销会大
- 索引体积较大,会占用更多存储空间
- 索引过多,选择性问题,难以管理
- 设计不合理导致冗余
- 局限在单表,多表嵌套复杂查询会让覆盖索引显得鸡肋
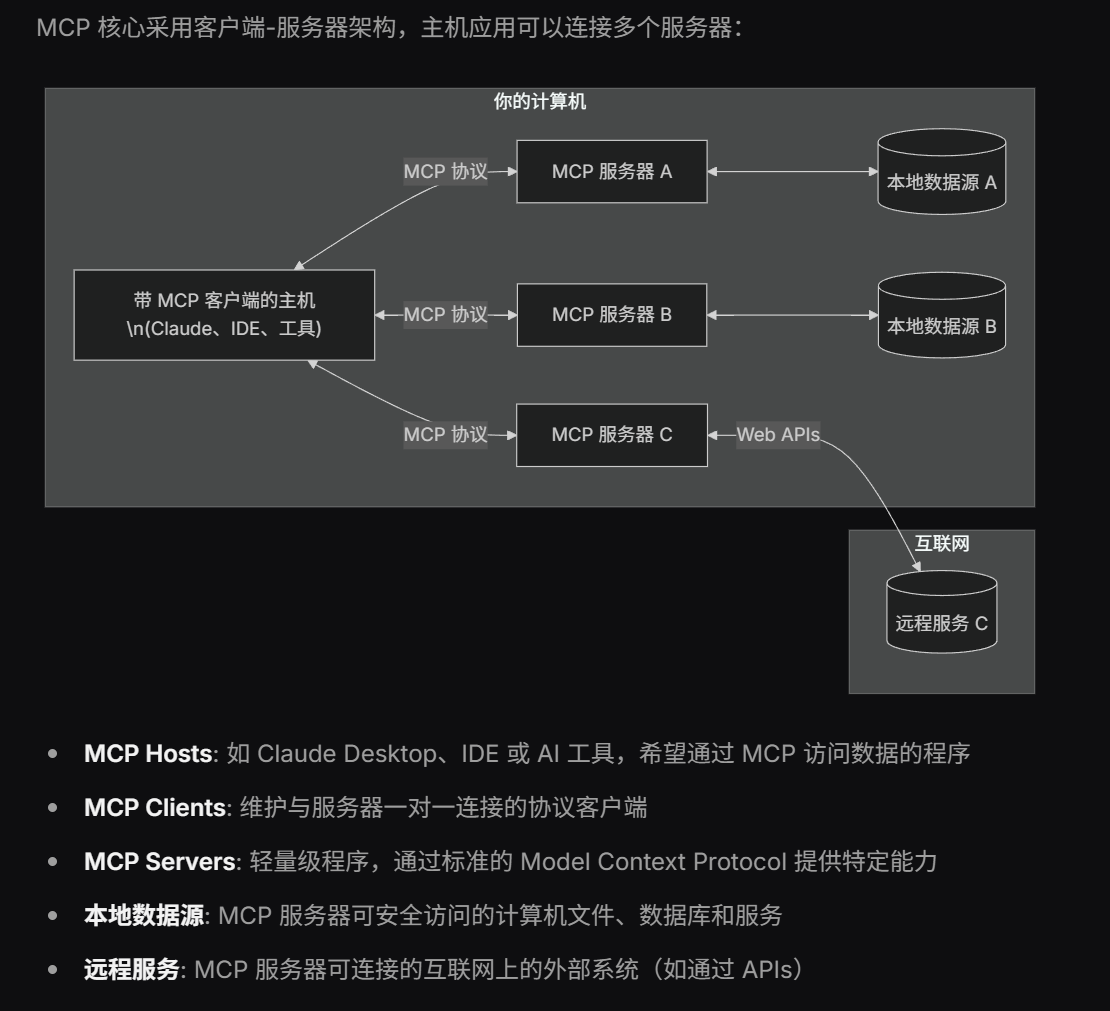
MCP协议,A2A协议(技术视角如何看待MCP协议,MCP算不算接口协议,和HTTP有什么区别)
MCP技术定位
MCP是一种用于连接LLM与外部资源的协议或框架(一句话描述)
- 如何描述一个外部资源(比如 API、数据库、文件系统等)—— 称为 MCP Server / MCP Resource
- 如何让 LLM 理解并安全地使用这些资源
- 如何在本地或云端运行一个 MCP Host,作为 LLM 和这些外部资源之间的桥梁
MCP的主要组成部分
- MCP Server:提供具体能力的服务器,比如查询数据库、调用 API、读取本地文件等
- MCP Client / Host:运行在用户设备或云端的中间层,负责与 LLM 引擎通信,并路由请求到正确的 MCP Server
- MCP 协议 / 规范:定义了 LLM 如何发现、调用这些外部能力,通常基于 JSON、WebSocket 或自定义轻量协议
MCP和HTTP的区别
| 维度 | MCP 协议 | HTTP 协议 |
|---|---|---|
| 定位 | 用于连接 大语言模型(LLM)与外部工具/数据源,是 LLM 生态中的“能力接入协议” | 通用的 应用层通信协议,用于客户端与服务器之间的请求-响应交互 |
| 交互主体 | 主要用于 LLM 与工具/数据源之间(通过 MCP Host 中转) | 用于 任意两个网络节点之间(如浏览器与服务器、客户端与服务端) |
| 通信模式 | 通常是 LLM 主动查询或调用外部能力,背后可能封装了 HTTP / gRPC 等实际协议 | 主要为 请求-响应(Request-Response)模式,也有 WebSocket 等变种 |
| 设计目标 | 让 LLM 能理解和使用外部工具,具备“上下文感知”和“操作能力” | 实现网络中标准化的数据传输与远程调用 |
| 协议层级 | 可以基于 TCP / WebSocket / HTTP,属于更上层 应用逻辑协议 | 应用层基础协议,定义了通用的报文格式、状态码、方法(GET/POST等) |
| 是否标准化 | 目前是 Anthropic 主导的 新兴协议,尚未完全标准化 | 是互联网的 标准协议之一,广泛使用且有成熟生态 |
| 典型用途 | 让 Claude 等 LLM 能调用本地文件、数据库、API 等上下文 | Web 服务、API 调用、微服务通信等 |
Http和WebSocket的性能问题
HTTP性能问题
- 通信单向不持久
- 头部冗余,延迟高,不适合实时推送
- 长轮询带来额外开销和延迟
- 无法服务端推送
WebSocket性能优势
- 全双工实时通信,只有一次TCP连接
- 复用长连接,连接开销小
- 消息开销小,没有像http那样笨重的头部
WebSocket性能问题
连接管理复杂度高
- 有状态,长连接
- 服务端需要维护大量并发连接,处理连接保活,管理连接状态,心跳,短线重连,负载均衡等等
缺乏内置流量控制,消息确认机制
不提供消息重传,确认,顺序保证,流量控制等高级机制
表索引优化过程删除策略的考虑和评估如何去做
性能损耗的来源
| 数据行删除 | 从表数据页中移除记录,可能引发页重组 |
|---|---|
| 2. 索引维护 | 每条删除的记录,都会在每一个相关索引中删除对应的索引项,这是性能开销的大头 |
| 3. 事务与日志 | 如果使用事务(如 InnoDB),需要记录 undo log、redo log,保证一致性 |
| 4. 锁竞争 | 大批量删除可能锁住很多行或页,阻塞其他查询和写入 |
| 5. 自动膨胀与碎片 | 删除后数据页可能留有空洞,导致表空间膨胀与查询性能下降 |
如何评估
数据库自带索引统计
-- 查看索引使用情况(MySQL 8.0+ 推荐) SELECT * FROM sys.schema_index_statistics; -- 或 SELECT * FROM information_schema.INDEX_STATISTICS;
-- 或查看未被使用的索引(需开启 performance_schema 或使用 sys 库) SELECT * FROM sys.schema_unused_indexes;
关注索引是否真正被使用过,选择性,维护成本和查询收益
开启慢sql日志
通过表关联查询,人工排查慢sql日志
删除策略采取分批次,流量小的时间段删除
CAS具体的应用场景
原子类
乐观锁
基于AQS的Reentranlock,Countdownlatch,Semphore这些他们的状态都是运用了cas思想
FutureTask任务状态的原子变更
ES-Mysql缓存一致性的保证
Spring核心
核心设计思想
控制反转
抛弃传统JAVA new对象,改用容器控制Bean的生命周期
面向切面编程AOP
基于动态代理,运行将横切逻辑织入目标方法执行的前后,周围或异常时,实行非侵入式的功能增强
依赖注入DI
对象之间的依赖关系不由对象自己控制,二十由外部容器注入进来,从而实现解耦和可测试性
容器化,组件化设置
将诸如Service,DAO,Controller看作Bean,统一由容器管理
模块化和分层架构设计
Spring 框架本身是一个分层、模块化的架构,每个模块职责单一,可插拔,主要包括:
| 模块 | 功能描述 |
|---|---|
| Core Container(核心容器) | 包括 Beans、Core、Context、SpEL 模块,是 Spring 的基础,提供 IoC 和 DI 能力 |
| AOP & Instrumentation | 提供面向切面编程支持和类加载期/运行期增强 |
| Data Access / Integration | 包括 JDBC、ORM、事务管理(Transaction)、JMS 等数据访问相关模块 |
| Web 模块 | 包括 Web MVC、WebSocket、Servlet 等,用于构建 Web 应用 |
| Test 模块 | 提供对 JUnit / TestNG 的良好支持,方便单元测试和集成测试 |
模板方法与回调机制
大量使用模板方法模式,例如很多的Template类
- dbcTemplate:封装了 JDBC 的模板流程(获取连接、执行 SQL、处理结果、释放资源),开发者只需关注业务 SQL 和回调逻辑
- RestTemplate / WebClient:HTTP 请求的模板化封装
- TransactionTemplate:事务管理的模板化抽象
约定优于配置
“约定优于配置” 就是:你按照我(框架)推荐的标准方式来做事情,很多事情我自动帮你搞定,你不用操心;只有你想不一样,才需要自己去配置。
核心设计模式
控制反转
依赖注入
工厂模式
典型用例是ApplicationContext
单例模式
默认单例
代理模式
AOP动态代理
模板方法模式
大量的Template封装类
观察者模式
SpringEvent的事件监听机制
策略模式
事务管理策略,多种数据源路由策略等等
适配器模式
HandlerAdapter,HandlerMapping等用于MVC的扩展
核心设计原则
依赖倒置原则
IOC和DI
开闭原则
允许扩展,拒绝修改,比如Bean生命周期中的前置和后置扩展接口
单一职责原则
每个模块,每个类职责清晰
接口隔离与组合原则
大量使用接口定义行为
可扩展性,松耦合
面向接口编程,事件机制,AOP等实现组件间松耦合
拦截器和过滤器的区别,实际的应用
Filter 是 Servlet 规范的一部分,作用于所有进入 Web 容器的请求,更底层、更全局;Interceptor 是 Spring MVC 提供的机制,作用于 Controller 层,更灵活、更贴近业务,且能方便使用 Spring Bean。两者可以结合使用,分别处理不同层次的逻辑。
- Filter 用来处理 HTTP 通用逻辑(如编码、跨域、安全过滤等)
- Interceptor 用来处理与业务相关的控制逻辑(如权限、用户身份、日志等)
- 两者可以搭配使用,比如用 Filter 做 Token 校验前处理,Interceptor 做更细粒度的权限判断。
途虎
线程池的工作流程
这个核心的问题是什么时候入队,是核心线程已满时就会入队,队列满的时候创建非核心线程,
当已经超过线程池的最大核心线程数后才会触发拒绝策略。
一直有大批量的流量进来如何处理(双十一秒杀场景)
流量入口层
前端/客户端限流
- 静态资源缓存
- 按钮防重复点击
- 本地缓存
网关层限流与熔断
- 流量清洗:通过Ngnix或云厂商(AWS API Gateway)设置速率限制,基于IP或者用户ID限流
- 动态限流:结合实时流量监控,动态调整限流阈值
- 熔断降级:当下游服务(如库存服务,订单服务)出现故障或延迟过高时,网关直接返回降级响应,避免级联崩溃。
负载均衡
使用Nginx,F5或者云厂商负载均衡,将流量均匀分发到多个应用服务器,避免单节点过载。
应用层
库存预热与缓存扣减
秒杀开始前将热门商品库存从数据库加到Redis,避免秒杀大量请求直接击穿数据库,使用Redis的DECR命令原子扣减库存,避免引发并发问题
异步处理下单请求
将生成订单等非实时操作通过消息队列异步处理,削平流量峰值
防超卖与分布式锁
超卖问题:多个请求同时扣减库存时,可能因数据库事务延迟导致超卖(如库存剩1,但两个请求都认为库存足够)。
解决方案:
- 数据库层面:使用乐观锁(
UPDATE stock SET count=count-1 WHERE sku_id=? AND count>=1),通过版本号或条件判断保证原子性。 - 分布式锁:对同一商品的库存操作加锁(如Redis的
RedLock),确保同一时间只有一个线程能扣减库存(需注意锁粒度,避免影响性能)。
服务层
1. 水平扩容
- 应用服务器:通过Kubernetes(K8s)或云厂商的弹性伸缩(Auto Scaling)功能,根据CPU、内存或QPS指标自动增加实例(如流量激增时,5分钟内从10台扩展到100台)。
- 数据库:
- 读写分离:主库写(订单、库存扣减),从库读(商品信息查询),减轻主库压力。
- 分库分表:对订单库按用户ID或时间分片(如按月份分表),避免单库数据量过大。
2. 服务降级
- 关闭非核心功能:秒杀期间,暂时关闭“商品评论”“推荐系统”“优惠券计算”等非必要服务,减少服务间调用链路,降低系统负载。
- 简化业务流程:例如,下单时不强制校验用户的积分余额(后续补扣),或跳过部分日志记录(关键日志保留)。
3. 热点隔离
- 将秒杀商品单独部署为一组服务实例(如“秒杀服务集群”),与日常商品服务隔离,避免热点流量影响其他业务。
- 使用独立数据库或缓存集群(如Redis Cluster的分片),确保热点数据的操作不影响其他业务的存储资源。
监控与应急
全链路监控
- 指标监控:采集QPS、延迟(RT)、错误率、数据库慢查询、Redis命中率等指标,通过Prometheus+Grafana或阿里云ARMS可视化展示。
- 链路追踪:使用Jaeger、SkyWalking或阿里云链路追踪,定位耗时最长的链路节点(如某个SQL查询占比80%),针对性优化。
- 日志分析:通过ELK(Elasticsearch+Logstash+Kibana)或阿里云SLS收集日志,实时搜索异常关键词(如
OutOfMemoryError、RedisTimeout)。
应急预案
- 手动限流:当自动限流触发后,若流量仍持续增长,可通过后台手动调整限流阈值(如将IP限流从10次/秒降至5次/秒)。
- 紧急扩容:预设扩容模板(如“秒杀场景专用实例组”),流量激增时一键触发扩容。
- 流量切换:若部分服务不可用,通过网关将流量切换到备用集群(如从“生产集群”切换到“灾备集群”)。
Syschornized锁升级过程
Mark Word字段
| 锁状态 | Mark Word 结构(64 位 JVM) |
|---|---|
| 无锁 | 存储对象的哈希码(HashCode)、分代年龄(GC Age)、锁标志位(01) |
| 偏向锁 | 存储偏向线程 ID、偏向时间戳(Epoch)、对象分代年龄、锁标志位(01) |
| 轻量级锁 | 存储指向栈中锁记录的指针、对象分代年龄、锁标志位(00) |
| 重量级锁 | 存储指向 Monitor(监视器)的指针、对象分代年龄、锁标志位(10) |
锁升级的过程
1. 无锁状态(初始状态)
对象刚创建时,未被任何线程访问,处于无锁状态。此时 Mark Word 的锁标志位为 01,存储对象的哈希码、分代年龄等信息。
2. 偏向锁(无竞争或低竞争场景)
目标:优化 只有一个线程访问同步块 的场景,避免重复加锁。
触发条件:
当第一个线程(线程 A)访问同步块时,JVM 会检查对象头的 Mark Word 是否为无锁状态(锁标志位 01)。若为无锁,线程 A 会通过 CAS(Compare-And-Swap)操作 尝试在对象头的 Mark Word 中记录自己的 线程 ID 和 偏向时间戳(Epoch),并将锁标志位改为 01(标记为偏向锁)。
偏向锁的特性:
- 线程 A 再次进入同步块时,无需 CAS 操作,直接通过检查 Mark Word 中的线程 ID 是否为自身,即可进入同步块(“偏向”该线程)。
- 若其他线程(线程 B)尝试获取偏向锁:
- 线程 B 会先检查 Mark Word 中的偏向时间戳是否过期(默认永不过期,除非发生竞争)。
- 若未过期,线程 B 会发起 CAS 竞争锁,但此时 Mark Word 已被线程 A 占用,CAS 会失败。
- 线程 A 被唤醒后,发现是其他线程竞争,会 撤销偏向锁(将锁标志位改为
01,并清空线程 ID),然后升级为轻量级锁。
3. 轻量级锁(低竞争场景)
目标:优化 多个线程交替执行同步块(竞争不激烈)的场景,避免重量级锁的线程阻塞开销。
触发条件:
当存在第二个线程(线程 B)竞争偏向锁时,偏向锁会膨胀为轻量级锁。
轻量级锁的加锁过程:
- 线程 A 和线程 B 各自在自己的 线程栈帧 中创建一个 锁记录(Lock Record),用于存储对象头的 Mark Word 的拷贝(称为 Displaced Mark Word)。
- 线程尝试通过 CAS 操作 将对象头的 Mark Word 替换为指向锁记录的指针:
- 若 CAS 成功(仅一个线程成功),该线程获得锁,锁标志位改为
00(轻量级锁)。 - 若 CAS 失败(另一个线程也尝试获取锁),说明存在竞争,轻量级锁会膨胀为重量级锁。
- 若 CAS 成功(仅一个线程成功),该线程获得锁,锁标志位改为
轻量级锁的解锁过程:
线程通过 CAS 将锁记录中的 Displaced Mark Word 替换回对象头的 Mark Word:
- 若成功,锁释放;
- 若失败,说明有其他线程尝试获取该锁,锁会膨胀为重量级锁。
4. 重量级锁(高竞争场景)
目标:处理 多线程频繁竞争 的场景(如秒杀、高并发请求)。
触发条件:
当多个线程(≥2)同时竞争轻量级锁,且 CAS 操作频繁失败时,轻量级锁会膨胀为重量级锁。
重量级锁的实现:
- 对象头的 Mark Word 会存储指向 Monitor(监视器) 的指针,锁标志位改为
10。 - Monitor 内部维护一个 等待队列(Entry Set) 和一个 条件队列(Wait Set),所有未获取到锁的线程会被加入等待队列并阻塞(通过操作系统内核挂起)。
- 当持有锁的线程释放锁时,会唤醒等待队列中的一个线程重新竞争锁。
Mysql索引失效
什么是幻读,如何解决的
幻读解决方案
提升隔离级别至串行化
利用间隙锁和邻键锁
1)间隙锁(Gap Lock)
锁定索引记录之间的“间隙”,防止其他事务在该间隙插入新记录。
- 适用场景:针对
范围查询(如WHERE id BETWEEN 10 AND 20)。 - 原理:若查询条件使用索引,数据库会锁定该范围的前后间隙(如锁定
(10,20)区间),其他事务无法在该区间插入新记录(即使新记录的 ID 是 15)。
(2)临键锁(Next-Key Lock)
行锁与间隙锁的组合,锁定 当前索引记录 + 前一个间隙,是 MySQL InnoDB 在 可重复读隔离级别下解决幻读的核心机制。
- 示例:查询
id = 15的记录(假设id是主键且有索引),临键锁会锁定(10,15]区间(包含 15 本身及前一个间隙(10,15))。 - 效果:其他事务无法插入
id = 15(被行锁阻止),也无法插入id = 11~14(被间隙锁阻止),从而避免幻读。
如何利用间隙锁和邻键锁解决幻读?
间隙锁和邻键锁通过 锁定查询范围的间隙和现有记录,阻止其他事务插入或修改符合条件的数据,从而保证同一事务内多次查询结果的一致性。具体实现中:
- 间隙锁 专注于锁定“无记录的区间”,防止插入新记录;
- 邻键锁 结合行锁和间隙锁,同时防止插入和修改现有记录;
- InnoDB 在
可重复读隔离级别下默认使用邻键锁,是解决幻读的核心机制。
实际应用中,需注意:
- 为查询条件设计合适的索引(避免全表扫描);
- 控制事务的执行时间(减少锁持有时间);
- 对高并发场景,可通过调整隔离级别(如
读已提交)或优化业务逻辑(如乐观锁)平衡一致性与性能。
文本切割过程中一些需要考虑的问题
歧义性与边界模糊
文本天然模糊性时切割的核心挑战,主要表现为词语边界不明确或语义单元重叠
典型问题:
- 中文分词歧义:如“乒乓球拍卖完了”可切割为“乒乓球拍/卖/完了”或“乒乓球/拍卖/完了”,需依赖上下文判断。
- 英文缩写与连字符:如“Mr. Smith”中的“Mr.”是缩写(非句子结束),“state-of-the-art”是复合词(需整体切割)。
- 标点干扰:引号内的句号(如
他说:“结束。”)不应作为句子结束符;括号内的内容(如注:(1)… (2)…)需保持局部完整性。
解决思路:
- 引入 统计模型(如CRF、LSTM、Transformer)捕捉上下文依赖,通过概率判断最优切割路径。
- 构建 领域词典 补充未登录词(如网络新词、专业术语),减少未登录词导致的歧义。
- 设计 规则后处理(如正则表达式),针对特定模式(如缩写、引号内的标点)修正切割结果。
特殊字符与噪声干扰
典型问题:
- 字符编码问题:如UTF-8与GBK混用导致乱码(如“我是ä¸æ–‡”),需先统一编码。
- 全角/半角混合:如“你好world”中的全角空格与半角字母,需标准化为统一格式。
- 噪声内容:如“【广告】点击领取”中的冗余标签,或“啊啊啊啊”等无意义重复字符。
解决思路:
- 预处理清洗:通过正则表达式过滤乱码(如非UTF-8字符)、统一全角/半角(如将“w”转为“w”)、去除冗余标签(如广告前缀)。
- 噪声鲁棒性训练:在模型训练数据中加入噪声样本(如随机插入重复字符),提升模型对噪声的容忍能力。
多语言与领域适应性
不同语言的语法结构差异大,且特定领域(如医疗、法律)的文本包含专业术语,通用切割方法可能失效。
解决方案
多语言模型适配和构建领域词典,进行领域定制化
长上下文依赖与长距离关联
部分单元文本切割需要依赖长距离上下文,局部信息不足以判断边界
解决思路
使用长文本建模捕捉长距离依赖,结合篇章分析识别语义单元,在切割时保留逻辑连贯性。
性能与效率问题
处理大规模文本(如日志文件、海量文档)时,需平衡切割准确性与计算效率。
典型问题:
- 模型复杂度高:基于深度学习的模型(如BERT)推理速度慢,难以处理实时或海量数据。
- 内存占用大:长文本处理时,模型输入长度限制(如Transformer的512 token限制)可能导致截断,丢失关键信息。
解决思路:
- 轻量级模型:采用轻量级架构(如BiLSTM+CRF)或模型压缩(如知识蒸馏、量化)提升推理速度;
- 分块处理:对长文本按固定长度(如512 token)分块,结合上下文窗口(如滑动窗口)保留跨块关联;
- 并行计算:利用GPU/TPU加速模型推理,或通过多线程/分布式处理批量文本。
标注数据与模型泛化
监督学习方法依赖高质量标注数据,但标注成本高,且模型可能因数据分布偏移(如领域变化)失效。
典型问题:
- 标注数据不足:垂直领域(如医疗)缺乏标注语料,通用数据难以直接应用。
- 领域偏移:模型在训练集(如新闻文本)上效果好,但在目标领域(如社交媒体)上性能下降。
解决思路:
- 半监督/无监督方法:利用少量标注数据+大量未标注数据(如自训练、对比学习)提升模型泛化能力;
- 迁移学习:基于预训练模型(如BERT)在目标领域微调,减少对标注数据的依赖;
- 主动学习:通过模型不确定性采样(如预测置信度低样本)优先标注关键数据,降低标注成本。
评估与验证
切割结果的评估需设计合理的指标,并覆盖真实场景的多样性。
典型问题:
- 指标单一:仅用准确率(Accuracy)可能忽略边界模糊的模糊案例(如“乒乓球拍卖完了”的两种切割均有一定合理性)。
- 测试集覆盖不足:测试数据与实际场景(如领域、语言风格)差异大,导致评估结果不可靠。
解决思路:
- 多维度指标:结合准确率、召回率、F1值,以及边界错误率(Boundary Error Rate)评估切割精度;
- 人工评估:针对模糊案例(如歧义句)设计人工评分标准,补充自动指标的不足;
- 领域测试集:构建与目标场景一致的测试集(如医疗文本、社交媒体文本),验证模型泛化能力。
消息堆积生产端速率如何做控制
解决核心操作
- 利用消息队列自带的参数限制调整生产者的生产速率
- 利用限流算法,漏桶或者令牌桶进行限流
- 背压机制,通过消费端的反馈动态调整生产速率
消息堆积的核心原因与影响
- 核心原因:生产端速率(P)> 消费端速率(C),且持续时间超过系统缓冲能力。
- 典型影响:
- 存储资源耗尽(如Kafka分区磁盘写满、RocketMQ CommitLog磁盘溢出);
- 网络带宽占用过高(生产端大量发送导致网络拥塞);
- 消费端负载过重(线程/连接数被打满,处理延迟激增);
- 级联故障(如消费端处理失败触发重试,进一步加剧堆积)。
核心目标
- 避免堆积恶化:通过限制生产速率,使(P ≤ C + 缓冲容量),为消费端争取处理时间。
- 平滑流量波动:将突发的流量高峰(如秒杀、大促)转化为稳定的流量输出。
- 保护系统资源:防止网络、磁盘、内存等资源被生产端耗尽。
具体策略
- 流量整形(Traffic Shaping):通过算法(如令牌桶、漏桶)将突发流量平滑为稳定流。
- 动态调参:根据实时监控数据(如消费端TPS、队列堆积量)调整速率上限。
- 队列隔离:通过多队列或优先级队列区分消息类型,针对性控制速率。
缓存击穿,缓存穿透,缓存雪崩
| 特征 | 缓存击穿 | 缓存穿透 | 缓存雪崩 |
|---|---|---|---|
| 触发条件 | 单个热点 Key 过期 | 查询不存在的数据 | 大量 Key 集中过期/缓存宕机 |
| 请求特征 | 瞬时高并发请求(同一 Key) | 大量无效请求(不存在的 Key) | 海量请求(所有 Key 失效) |
| 核心问题 | 热点 Key 过期后的瞬时洪峰 | 无效 Key 绕过缓存 | 缓存失效或宕机导致的全量洪峰 |
| 解决方案 | 互斥锁、提前更新、多级缓存 | 缓存空值、布隆过滤器、参数校验 | 分散过期时间、多级缓存、限流降级 |
MCP的组成部分
消息的顺序性如何保证
常见限流算法总结
固定窗口限流
将单位时间段作为一个窗口,计数器记录这个窗口接收请求的次数
- 当次数少于限流阀值,就允许访问,并且计数器+1
- 当次数大于限流阀值,就拒绝访问。
- 当前的时间窗口过去之后,计数器清零。
固定窗口限流算法存在临界问题,假设限流阀值为5个请求,单位时间窗口是1s,如果我们在单位时间内的前0.8-1s和1-1.2s,分别并发5个请求。虽然都没有超过阀值,但是如果算0.8-1.2s,则并发数高达10,已经超过单位时间1s不超过5阀值的定义啦。
滑动窗口限流算法
把窗口划分为小周期来解决固定窗口的临界问题

漏桶算法
核心参数
容量,漏水速率,拒绝策略
算法特点
- 平滑流量
- 严格速率控制
- 容量限制
算法实现
package org.example;
import java.util.LinkedList;
import java.util.Queue;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class LeakyBucket {
private final int capacity;
private final int rate;
private final Queue<Long> bucket;
private long lastUpdateTime;
private final Lock lock;
public LeakyBucket(int capacity, int rate) {
if (capacity <= 0 || rate <= 0) {
throw new IllegalArgumentException("容量和速率必须大于0");
}
this.capacity = capacity;
this.rate = rate;
this.bucket = new LinkedList<>();
this.lock = new ReentrantLock();
this.lastUpdateTime = System.currentTimeMillis();
}
public boolean allow(){
lock.lock();
try {
long currentTime = System.currentTimeMillis();
long timePassed = currentTime - lastUpdateTime;
int numToLeak= (int) (timePassed * rate/ 1000 );
if (numToLeak > 0){
int actualLeak= Math.min(numToLeak, bucket.size());
for (int i = 0; i < actualLeak; i++) {
bucket.poll();
}
}
if (bucket.size() < capacity){
bucket.offer(currentTime);
return true;
}
else return false;
}
finally {
lock.unlock();
}
}
}
令牌桶算法
| 特性 | 令牌桶算法 | 漏桶算法 |
|---|---|---|
| 处理逻辑 | 请求需获取令牌(令牌由系统主动投放) | 请求直接进入桶,桶以固定速率“漏水” |
| 突发容忍度 | 允许(桶容量决定最大突发) | 不允许(仅桶容量内的突发被缓存) |
| 速率控制 | 平均速率固定,允许瞬间超速 | 严格固定速率(无超速可能) |
| 典型场景 | API 限流(允许合理突发) | 流量整形(严格要求平滑输出) |
算法实现
package org.example;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class TokenBucket {
private final int capacity;
private final int rate;
private int tokens;
private long lastRefillTime;
private final Lock lock;
public TokenBucket(int capacity, int rate) {
if (capacity <= 0 || rate <= 0) {
throw new IllegalArgumentException("容量和速率必须大于0");
}
this.capacity = capacity;
this.rate = rate;
this.tokens = capacity;
this.lastRefillTime = System.currentTimeMillis();
this.lock = new ReentrantLock();
}
private void refillTokens() {
long currentTime = System.currentTimeMillis();
long timePassed = currentTime - lastRefillTime;
int tokensToAdd = (int) (timePassed * rate / 1000);
if (tokensToAdd > 0) {
tokens = Math.min(capacity, tokens + tokensToAdd);
lastRefillTime = currentTime;
}
}
public boolean tryAcquire() {
return tryAcquire(1);
}
public boolean tryAcquire(int requiredTokens) {
if (requiredTokens <= 0) {
throw new IllegalArgumentException("所需令牌数必须大于0");
}
if (requiredTokens > capacity) {
return false;
}
lock.lock();
try {
refillTokens();
if (tokens >= requiredTokens) {
tokens -= requiredTokens;
return true;
} else return false;
} finally {
lock.unlock();
}
}
}
Vesync
QPS,相同qps下,使用多线程对于服务器各种资源的影响
cpu资源
- 正面:对于IO密集型操作(数据库查询,文件读写),线程在等待IO时会主动让出CPU,多线程可让其他线程占用空闲的cpu核心处理请求,避免cpu空闲,显著提升cpu利用率。
- 对于弱CPU密集型(加密计算+IO混合),合理增加线程数可隐藏IO延迟,使CPU持续忙碌
- 负面:对于CPU密集型任务(加密计算+IO混合),线程数超过CPU核心数,操作系统通过时间片轮转调度线程,导致频繁的上下文切换,这会消耗CPU资源
内存资源
- 栈空间线性增长:线程数增加,每个线程需要独立的运行栈,导致内存占用增加,或者触发Swap,严重影响性能。
- 共享数据的内存副本:若线程间需要传递或者拷贝数据(如请求上下文),增加内存复制开销
- 线程本地存储:部分框架使用TLS缓存线程私有数据(如数据库连接),线程数增加导致TLS内存碎片化,肯恩降低内存访问效率。
IO资源
- 同步IO:单线程处理同步I/O时会阻塞等待响应(如调用
read()读取磁盘文件),此时CPU空闲。多线程可让其他线程继续执行(如处理新请求),提升I/O设备的并发利用率(如磁盘队列被多个线程的请求填满,减少寻道空闲)。 - 异步IO:异步I/O(如Linux AIO、epoll)通过事件驱动避免线程阻塞,此时多线程的必要性降低。若强行使用多线程处理异步事件,可能因线程调度延迟抵消异步优势,增加内存和CPU开销。
网络资源:
- 连接并发与端口消耗:每个线程可能绑定一个网络连接(如短连接场景),线程数增加会导致同时活跃的TCP连接数上升,消耗更多端口号(客户端)或服务端连接表项(如Linux
net.core.somaxconn限制)。 - 网络栈资源竞争:多线程发送/接收数据时,可能竞争网卡驱动、协议栈(如TCP/IP校验和计算)的资源,导致延迟波动。但现代网卡支持多队列(RSS),可将流量分散到不同CPU核心,缓解竞争。
- 带宽利用率:若QPS相同,总网络流量(字节/秒)通常不变,但多线程可通过并行发送/接收数据包,减少单个连接的延迟,间接提升整体吞吐效率(如更快的响应时间允许客户端更快发送下一个请求)。
锁竞争与同步开销
多线程共享资源(如全局计数器、缓存、数据库连接池)时,需通过锁(互斥锁、自旋锁)或无锁机制同步,可能带来:
- 锁竞争导致的等待:若多个线程频繁竞争同一把锁(如热点数据的全局锁),线程会从运行态转为阻塞态,触发操作系统调度。此时CPU时间被浪费在等待锁上,而非实际任务处理。
- 锁粒度与性能:细粒度锁(如每个资源独立加锁)可减少竞争,但会增加锁管理的复杂度(如哈希表维护锁);粗粒度锁(如全局锁)简单但易成为瓶颈。
- 原子操作与内存屏障:无锁编程依赖原子指令(如CAS)和内存屏障,虽避免了显式锁,但可能增加CPU流水线的停顿(因内存顺序约束)。
上下文切换:线程调度的直接开销
线程数超过CPU核心数时,操作系统需通过上下文切换(Context Switch)调度线程。每次切换需:
- 保存当前线程的寄存器、栈指针、虚拟内存状态到内核栈;
- 加载下一个线程的状态并恢复执行。这一过程消耗CPU时间(通常几微秒到几十微秒),且:
- 用户态→内核态的切换会增加TLB(页表缓存)失效的概率,降低内存访问效率;
- 频繁切换可能导致CPU利用率“虚高”(内核态占比超过20%时需警惕),实际任务处理时间减少。
关于QPS的上限
qps上限的影响因素
QPS上限并非单一因素导致,而是系统各层级资源或逻辑瓶颈叠加的结果。常见场景可分为硬件资源瓶颈、软件架构限制、外部依赖约束三类:
1. 硬件资源瓶颈:底层物理限制
硬件是系统运行的基础,其性能上限直接决定了系统的QPS天花板,具体体现在以下组件:
- CPU:计算能力的边界**场景:CPU密集型任务(如加密计算、复杂算法推理、大规模数据压缩)。每个请求需消耗大量CPU周期(例如,一个请求需执行10ms的浮点运算),此时QPS上限由CPU核心数和单核心频率决定。例子**:4核CPU,单核心每秒可处理1000个10ms请求(1s/0.01s=100),总QPS上限约4×100=400。若线程数超过核心数,上下文切换开销会进一步压低实际QPS。
- 内存:数据存储与访问的限制**场景:内存密集型任务(如实时数据分析、缓存系统)。若请求需加载大量数据到内存(如每个请求需读取10MB数据到内存处理),内存带宽(数据读写速度)或容量会成为瓶颈。例子**:服务器内存带宽为50GB/s,每个请求需读写20MB数据,则每秒最多处理50×1024MB / 20MB ≈ 2560个请求,QPS上限约2560。若内存不足,还会触发Swap,导致延迟飙升甚至OOM崩溃。
- 磁盘I/O:持久化操作的延迟**场景:依赖磁盘写入的任务(如日志记录、数据库事务提交)。磁盘的IOPS(每秒输入输出次数)和延迟是核心限制。例子**:机械硬盘IOPS约100,SSD约5万。若每个请求需写入1次磁盘(如数据库事务),机械硬盘的QPS上限仅约100(即使CPU和内存空闲,磁盘也无法更快响应)。
- 网络带宽:数据传输的速率**场景:高流量传输场景(如文件下载、视频流服务)。QPS上限受限于网络接口的总带宽(如1Gbps带宽,每个请求响应需10KB数据,则QPS上限=1Gbps/(8×10KB)=约131,072)。例子**:若每个请求响应为1MB,1Gbps带宽的QPS上限仅约800(1Gbps=125MB/s,125MB/s ÷ 1MB/请求≈125请求/秒,受限于单个连接的处理能力,实际更低)。
2. 软件架构限制:逻辑与组件的瓶颈
即使硬件资源充足,软件架构的设计缺陷或组件限制也会直接导致QPS上限:
- 数据库连接池:并发请求的“闸门”**场景:依赖数据库的应用(如Web服务)。数据库连接池(如HikariCP)的大小决定了同时能与数据库建立连接的请求数。例子**:连接池配置为100,即使应用服务器有1000个线程,同时只有100个请求能等待数据库响应,其余线程需阻塞排队,QPS上限被限制在连接池大小附近(若每个连接每秒处理10个请求,总QPS≈100×10=1000)。
- 锁竞争与同步:共享资源的争抢**场景:多线程共享资源的场景(如全局计数器、缓存更新、分布式锁)。锁(互斥锁、自旋锁)会导致线程阻塞,降低并行效率。例子**:某热点数据的全局锁被100个线程竞争,每个线程持有锁的时间为1ms,即使CPU空闲,每秒最多处理1000个请求(1s/1ms=1000),锁竞争成为QPS上限的瓶颈。
- 线程/进程调度:操作系统开销**场景:高并发场景下的线程管理。线程数过多会导致频繁的上下文切换(用户态→内核态切换),消耗CPU时间。例子**:Linux系统上下文切换耗时约1~10μs,若每秒切换10万次,CPU时间浪费在切换上的占比可达10%以上,剩余时间才能处理实际请求,间接拉低QPS上限。
- 单实例部署:纵向扩展的极限**场景:未做分布式部署的单台服务器。无论硬件多强,单实例的QPS上限受限于上述所有资源的总和(如CPU+内存+磁盘的综合瓶颈)。例子**:单台服务器通过优化可将QPS提升至1万,但面对10万QPS的需求时,必须通过分布式架构(多实例负载均衡)突破单实例上限。
3. 外部依赖约束:上下游系统的牵制
系统的QPS上限不仅取决于自身,还受限于依赖的外部系统:
- 第三方API/服务:下游处理能力**场景:调用外部服务(如支付接口、短信验证码、地图API)。若第三方服务的QPS上限为1000,即使自身系统能处理1万QPS,整体QPS也会被限制在1000。例子**:电商大促时,支付接口的QPS上限为5000,即使订单系统能支撑10万QPS,实际订单创建QPS也只能达到5000。
- 消息队列:流量削峰的边界**场景:使用消息队列(如Kafka、RabbitMQ)缓冲请求。队列的吞吐量(如Kafka单分区每秒处理10万条消息)和消费端处理能力共同决定QPS上限。例子**:消息队列生产端QPS为10万,但消费端只有10个消费者,每个消费者每秒处理1000条消息,整体QPS上限仅1万(消费端成为瓶颈)。
如何实现一个下载逻辑,在后端生成一个excel文件,前端如何下载
核心是 后端直接返回文件流 和 前端正确处理Blob响应,避免中间文件落盘,同时解决文件名乱码、大文件性能等问题。
实现流程:
- 后端:生成Excel内容 → 写入响应输出流 → 设置
Content-Type和Content-Disposition响应头。 - 前端:发起请求(GET/POST)→ 接收文件流(
responseType: 'blob')→ 创建Blob对象 → 模拟<a>标签点击下载。
对接口做并行化优化后,可能导致接口qps显著提高的因素
- 单请求RT下降:通过APM工具(如SkyWalking)观察接口平均响应时间是否缩短;
- 线程利用率提升:监控线程池的活跃线程数、队列大小,确认线程是否从“阻塞等待”转为“忙碌处理”;
- CPU利用率提升:多核CPU的使用率是否从单核高负载转为多核均衡负载;
- IO等待时间占比下降:通过监控发现IO操作(如数据库、RPC)的耗时占比是否降低。
卓望公司
SpringBoot自动装配
Spring Boot 的自动装配(Auto-configuration)是其核心特性之一,旨在通过“约定大于配置”的原则,自动完成框架组件、第三方库的初始化和配置,大幅减少开发者的手动配置工作量。以下从机制、关键注解、实现原理、自定义扩展等方面详细解析。
一、自动装配的核心目标
Spring Boot 自动装配的目标是:根据项目依赖(如引入的 Starter)、类路径下的类、Bean 的存在与否等条件,自动创建并配置 Spring 上下文中的 Bean。例如:
- 引入
spring-boot-starter-web依赖,会自动配置 Tomcat、Spring MVC 相关组件; - 引入
spring-boot-starter-data-jpa依赖,会自动配置数据源、JPA 实体管理器等。
二、自动装配的关键注解
Spring Boot 自动装配的触发主要依赖以下几个核心注解:
@SpringBootApplication
这是 Spring Boot 主类的核心注解,是一个组合注解,包含:
@SpringBootConfiguration:标记当前类为配置类(等价于@Configuration);@ComponentScan:扫描当前包及子包下的@Component、@Service等组件;@EnableAutoConfiguration:触发自动装配的核心注解。
@EnableAutoConfiguration
该注解的作用是启用 Spring Boot 的自动配置机制。其底层通过 @Import导入了 AutoConfigurationImportSelector类,负责加载自动配置类。
@AutoConfiguration(Spring Boot 2.7+)
用于标记一个类为自动配置类(替代早期的 @Configuration配合条件注解的方式),明确告知 Spring Boot 这是一个自动配置类。
三、自动装配的实现原理
自动装配的核心流程可以分为以下几步:
1. 加载自动配置类
@EnableAutoConfiguration通过 AutoConfigurationImportSelector读取 META-INF/spring.factories 文件(位于 Spring Boot Starter 的 JAR 包中),获取所有需要加载的自动配置类列表。
spring.factories中定义的键为 org.springframework.boot.autoconfigure.EnableAutoConfiguration,值是一组自动配置类的全限定名(如 org.springframework.boot.autoconfigure.web.servlet.DispatcherServletAutoConfiguration)。
2. 过滤有效的自动配置类
加载到的自动配置类并非全部生效,需要通过条件注解(@Conditional系列)过滤。常见条件注解包括:
@ConditionalOnClass:当类路径下存在指定类时生效(如DispatcherServletAutoConfiguration要求DispatcherServlet存在);@ConditionalOnMissingBean:当容器中不存在指定 Bean 时生效(避免覆盖用户自定义的 Bean);@ConditionalOnProperty:当配置文件中存在指定属性时生效(如server.port控制服务器端口配置);@ConditionalOnResource:当类路径下存在指定资源时生效(如配置文件application.properties)。
3. 初始化自动配置的 Bean
过滤后的自动配置类会被实例化,其中的 @Bean方法会创建对应的 Bean 并注册到 Spring 容器中。这些 Bean 通常是框架或第三方库的核心组件(如数据源、Tomcat、MVC 控制器等)。
四、自动装配的典型示例
以 spring-boot-starter-web为例,自动装配过程如下:
- 引入
spring-boot-starter-web依赖后,其传递依赖会引入spring-webmvc、tomcat-embed-core等库; - Spring Boot 扫描
META-INF/spring.factories,找到DispatcherServletAutoConfiguration(DispatcherServlet 自动配置)、ServletWebServerFactoryAutoConfiguration(内嵌 Tomcat 配置)等; - 检查条件:类路径下存在
DispatcherServlet和Tomcat相关类,且容器中没有自定义的ServletWebServerFactory; - 自动创建
DispatcherServlet、TomcatServletWebServerFactory等 Bean,并完成 Web 环境的初始化。
五、自定义自动装配
如果需要为自己的库或组件添加自动装配能力,可以按以下步骤操作:
1. 创建自动配置类
定义一个类,使用 @AutoConfiguration(或 @Configuration)注解,并配合条件注解控制生效逻辑。例如:
@AutoConfiguration // 标记为自动配置类(Spring Boot 2.7+)
@ConditionalOnClass(MyService.class) // 当 MyService 存在时生效
public class MyAutoConfiguration {
@Bean
@ConditionalOnMissingBean // 容器中无 MyService 时才创建
public MyService myService() {
return new MyService();
}
}
2. 注册自动配置类
在 src/main/resources/META-INF/spring.factories文件中添加:
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\
com.example.MyAutoConfiguration
3. 测试验证
在项目中引入包含该自动配置类的依赖,Spring Boot 会自动加载并初始化 MyServiceBean(除非用户手动定义了 MyService)。
六、禁用自动装配
如果需要禁用某些自动配置类,可以通过以下方式:
- 在主类上使用
@SpringBootApplication的exclude参数:@SpringBootApplication(exclude = {DispatcherServletAutoConfiguration.class}) public class Application { ... } - 在
application.properties中配置:spring.autoconfigure.exclude=org.springframework.boot.autoconfigure.web.servlet.DispatcherServletAutoConfiguration
总结
Spring Boot 自动装配通过 @EnableAutoConfiguration触发,结合 spring.factories加载自动配置类,并通过条件注解动态过滤生效的配置。其核心是“约定大于配置”,通过依赖和类路径等信息自动完成组件初始化,极大简化了开发。开发者可以通过自定义自动配置类扩展这一机制,实现框架或业务组件的无缝集成。
常用Linux指令
文件目录类
ls [参数] | 列出目录内容 | ls -l(详细列表)、ls -a(显示隐藏文件)、ls /opt/app(查看指定目录) |
|---|---|---|
cd [路径] | 切换目录 | cd /opt/app(绝对路径)、cd ../(返回上级目录)、cd ~(回到用户家目录) |
mkdir [参数] | 创建目录 | mkdir -p /opt/app/logs(递归创建多级目录) |
rm [参数] | 删除文件/目录 | rm -f log.txt(强制删除文件)、rm -r logs/(递归删除目录) |
cp [参数] | 复制文件/目录 | cp app.jar /backup/(复制文件)、cp -r src/ target/(递归复制目录) |
mv [参数] | 移动文件/目录 或 重命名 | mv old.log new.log(重命名)、mv app.jar /opt/deploy/(移动文件) |
touch [文件] | 创建空文件 或 更新文件时间戳 | touch startup.sh(创建脚本文件) |
cat [文件] | 查看文件全量内容 | cat application.yml(查看配置文件) |
grep [参数] | 文本搜索(结合管道使用) | cat log.txt \| grep "ERROR"(过滤日志中的 ERROR 行)、grep -i "user" *.log(忽略大小写搜索当前目录所有日志) |
find [路径] | 查找文件/目录 | find /opt/app -name "*.jar"(查找所有 jar 文件)、find . -type f -size +10M(查找大于 10MB 的文件) |
tar [参数] | 打包/解压文件 | tar -zxvf app.tar.gz(解压)、tar -zcvf app.tar.gz ./app(打包) |
chmod [参数] | 修改文件/目录权限 | chmod 755 startup.sh(赋予所有者读写执行,其他用户读执行)、chmod u+x script.sh(仅所有者加执行权限) |
chown [参数] | 修改文件/目录所有者 | chown user:user app.jar(将文件所有者改为 user 用户和组) |
进程与服务管理
ps [参数] | 查看进程状态 | ps -ef \| grep java(查看所有 Java 进程)、ps -aux \| grep 8080(结合 grep 过滤端口相关进程) |
|---|---|---|
jps | 查看 Java 进程(JDK 自带工具) | jps -l(显示进程 PID 和主类全限定名) |
kill [参数] | 终止进程 | kill 1234(终止 PID 为 1234 的进程)、kill -9 1234(强制终止) |
top/ htop | 实时监控进程与系统资源 | 直接运行,查看 CPU、内存、进程占用排名(htop需额外安装,界面更友好) |
free [参数] | 查看内存使用情况 | free -h(以人类可读格式显示内存总量、已用、剩余) |
df [参数] | 查看磁盘空间使用情况 | df -h(显示各分区磁盘占用)、df -h /opt(查看指定目录所在分区) |
du [参数] | 查看目录/文件大小 | du -sh /opt/app(查看 app 目录总大小)、du -h --max-depth=1 /logs(查看 logs 下一级目录大小) |
日志查看与分析
tail [参数] | 查看文件末尾内容(实时监控) | tail -n 100 app.log(查看最后 100 行)、tail -f app.log(实时追踪新增日志) |
|---|---|---|
head [参数] | 查看文件开头内容 | head -n 50 app.log(查看前 50 行) |
less [文件] | 分页查看大文件(支持搜索) | less app.log(进入分页模式,按 /搜索关键字,q退出) |
sed [参数] | 文本替换(高级过滤) | sed -n '/2024-01-01 10:00:/,/2024-01-01 11:00:/p' app.log(提取某时间段日志) |
awk [参数] | 按列处理文本 | awk '{print $4}' access.log(打印日志第 4 列,如 HTTP 状态码 |
网络相关操作
ping [目标] | 测试网络连通性 | ping www.baidu.com(检查是否能访问外网) |
|---|---|---|
telnet [主机] [端口] | 测试端口是否开放 | telnet localhost 8080(检查本地 8080 端口是否被 Java 应用监听) |
nc [参数] | 网络工具(测试端口、传输文件) | nc -zv localhost 8080(验证端口是否开放) |
ifconfig/ ip addr | 查看网络接口信息 | ip addr show eth0(查看 eth0 网卡的 IP 地址) |
netstat [参数] | 查看网络连接与端口监听 | netstat -tlnp \| grep 8080(查看监听 8080 端口的进程) |
ss [参数] | 更高效的网络连接查看(替代 netstat) | ss -tlnp \| grep 8080(同上,性能更好) |
curl [URL] | 发送 HTTP 请求(测试接口) | curl http://localhost:8080/api/hello(检查接口是否返回预期结果) |
wget [URL] | 下载文件 | wget https://repo1.maven.org/maven2/spring-boot/spring-boot-starter-web/3.2.0/spring-boot-starter-web-3.2.0.jar(下载依赖包) |
环境变量设置
echo [变量] | 查看环境变量值 | echo $JAVA_HOME(查看 JDK 安装路径)、echo $PATH(查看可执行文件搜索路径) |
|---|---|---|
export [变量]=[值] | 临时设置环境变量 | export JAVA_HOME=/usr/lib/jvm/java-11-openjdk(临时修改 JAVA_HOME) |
source [文件] | 使配置文件生效(如 .bashrc) | source ~/.bashrc(让修改后的环境变量立即生效) |
vim [文件] | 编辑配置文件(如 .bashrc、application.yml) | vim ~/.bashrc(进入 vim 编辑器,按 i插入内容,ESC后 :wq保存退出) |
jvm调试工具
jstack [PID] | 打印线程栈(排查死锁、线程阻塞) | jstack 1234 > thread_dump.log(导出线程栈到文件分析) |
|---|---|---|
jmap [参数] | 生成堆转储文件(排查内存泄漏) | jmap -dump:format=b,file=heap.bin 1234(生成堆转储文件) |
jstat [参数] | 监控 JVM 统计信息(如 GC) | jstat -gcutil 1234 1000 5(每 1000ms 输出一次 GC 统计,共 5 次) |
jconsole | 图形化监控 JVM(需本地连接) | 直接运行,连接到远程 Java 进程(需开启 JMX 配置) |
直接使用ExcutorService创建线程池的弊端
| 无界队列导致OOM | LinkedBlockingQueue默认无界,任务堆积耗尽内存 |
|---|---|
| 线程数失控 | newCachedThreadPool无限创建线程,耗尽CPU/内存 |
| 默认拒绝策略激进 | 直接抛异常,中断业务流程 |
| 无法定制线程属性 | 线程名称、优先级等无法设置,不利于排查问题 |
| 无法适配业务场景 | “一刀切”配置无法满足秒杀、日志、批量操作等不同需求 |
JAVA中实现深拷贝
实现clonable接口
实现Serializable接口
使用第三方库
什么场景下会用到深拷贝
当满足以下条件时,必须使用深拷贝:
- 对象包含可变引用类型(如自定义对象、集合、数组);
- 需要独立副本,避免修改新对象影响原对象;
- 场景涉及状态保存、数据隔离、事务回滚、多线程/多用户安全等。
反之,若对象仅包含不可变类型(如String、Integer、基本类型),或明确允许共享修改,则浅拷贝即可满足需求。
金山办公
雪花算法
出现的机遇
- 数据库自增 ID:依赖中心化数据库,无法横向扩展,且多实例部署时易冲突。
- UUID:生成的无序字符串存储效率低,作为数据库主键时会严重影响索引性能。
- Redis 自增:依赖外部存储,增加系统复杂度和网络开销。
雪花算法通过本地生成的方式,避免了上述问题,同时保证 ID 的全局唯一性和有序性
核心结构
雪花算法生成的 ID 是一个 64 位的长整型(long),通常分为以下几部分(以经典实现为例):
| 部分 | 位数 | 描述 |
|---|---|---|
| 符号位 | 1 | 固定为 0,保证 ID 为正数(Java 中 long 最高位是符号位)。 |
| 时间戳(ms) | 41 | 记录生成 ID 的时间戳(毫秒级),通常相对于某个起始时间(如 2020-01-01)。 |
| 机器/节点 ID | 10 | 标识生成 ID 的节点(如服务器、容器),支持最多 210=1024个节点。 |
| 序列号 | 12 | 同一节点、同一毫秒内的自增序号,支持每毫秒最多 212=4096个 ID。 |
总长度:1 + 41 + 10 + 12 = 64 位(刚好是 Java 的 long 类型长度)。
关键设计细节
时间戳(41 位)
- 作用:保证 ID 随时间递增,避免重复(即使机器 ID 和序列号重置,时间戳也会递增)。
- 起始时间:通常选择一个业务相关的起始时间(如系统上线时间),例如 Twitter 使用
2010-11-04 09:42:54 UTC。41 位时间戳的最大值为 241−1毫秒 ≈ 69 年(从起始时间起算),足够支撑大多数系统的生命周期。
机器/节点 ID(10 位)
- 作用:区分不同节点,避免不同机器生成相同 ID。
- 分配方式:静态配置:手动为每个节点分配唯一 ID(如通过配置文件、环境变量)。动态分配:通过 ZooKeeper、Etcd 或数据库集中管理,节点启动时申请并注册 ID(需处理节点宕机后的 ID 回收)。简化方案:若节点数较少(如 < 1024),可直接用机器 IP 的后几位或哈希值。
序列号(12 位)
- 作用:同一节点、同一毫秒内,通过自增序列号避免 ID 重复。
- 规则:每毫秒开始时,序列号重置为 0;同一毫秒内每生成一个 ID,序列号加 1(最大到 4095)。若超过 4095,则等待下一毫秒再生成。
缓存IO和直接IO
| 维度 | 缓存 IO | 直接 IO |
|---|---|---|
| 数据路径 | 应用 → 内核页缓存 → 磁盘 | 应用 ↔ 磁盘(绕过内核缓存) |
| 缓存利用 | 利用预读、后写等缓存优化 | 不使用内核缓存 |
| 数据一致性 | 可能存在缓存延迟(需 fsync()同步) | 数据直接落盘(或应用控制刷盘时机) |
| 内存开销 | 占用系统页缓存 | 不占用系统缓存 |
| 适用 I/O 类型 | 小随机读、多次访问相同数据 | 大文件顺序读写、实时性要求高的场景 |
| 编程复杂度 | 简单(默认行为) | 需处理内存对齐、显式刷盘等 |
怎么减小dockerfile的大小
- 选择极简基础镜像,优先选择轻量级的
- 合并RUN指令并清理缓存,Docker 镜像的每一层都会保留文件变更,若在多个
RUN中安装包并清理缓存,缓存会被保留在中间层。必须在同一层内完成安装和清理,避免冗余文件。 - 清理其他临时文件,比如编译工具
- 多阶段构建,在构建阶段使用大体积镜像完成编译,最终阶段从构建阶段复制编译后的二进制文件到极简镜像
- 移除冗余文件,只保留必要的运行环境
如何排查CPU飙高的问题
确认基本信息
通过监控系统(如 Prometheus+Grafana、Zabbix)查看:
- 是单台服务器还是多台集群同时出现?
- CPU 是持续高(如 80%+ 超过 10 分钟)还是偶发峰值?
- 用户态(User)、内核态(Sys)、等待 I/O(Wait)占比如何?(
top命令输出的%Cpu(s)行:us用户态,sy内核态,waI/O 等待)
定位高CPU进程
使用 top或 htop快速定位消耗 CPU 最多的进程:
top -c # 显示完整命令,按 P 按 CPU 排序
- 观察
%CPU列,找到占用最高的进程 PID(如 PID=1234)。
定位进程内的高CPU线程
进程是线程的容器,需进一步定位进程内具体哪个线程在消耗 CPU。
查看进程的线程 CPU 使用情况
# 方法 1:top 查看线程(-H 表示线程模式)
top -Hp 1234 # 1234 是进程 PID,按 P 按线程 CPU 排序
# 方法 2:ps 输出线程信息(-L 显示线程)
ps -Lfp 1234 # 显示进程 1234 的所有线程,%CPU 列为线程 CPU 占比
- 记录高 CPU 线程的 TID(线程 ID,十进制)。
抓取线程栈
用 jstack 抓取线程栈
将线程 TID 转换为十六进制(Java 栈中的线程 ID 是十六进制):
printf "%x
" 1234 # 输出如 4d2(十进制 1234 → 十六进制 4d2)
抓取线程栈:
jstack 1234 > jstack.log
在 jstack.log中搜索十六进制 TID(如 nid=0x4d2),查看线程状态:
RUNNABLE:正在执行 Java 代码(可能是死循环或计算密集型任务)。BLOCKED:等待锁(可能锁竞争激烈)。TIMED_WAITING:等待sleep或wait(通常不消耗 CPU,除非被错误唤醒)。
结合 GC 日志分析
若线程栈显示 GC task thread高 CPU,可能是频繁 Full GC:
# 查看 GC 日志(需应用开启 -Xlog:gc*)
tail -f /path/to/gc.log | grep "Full GC"
频繁 Full GC 可能因内存泄漏或堆内存过小导致。
其他一些会引起CPU飙高的因素
- 代码问题:死循环、低效算法、频繁对象创建(Java GC 压力)。
- 资源竞争:锁争用、线程池配置不合理(线程数过多)。
- 外部因素:流量激增、恶意请求、依赖服务延迟导致重试。
- 系统问题:中断过多、上下文切换频繁、内核参数配置不当。
B+树索引详解
在数据库中,聚簇索引(Clustered Index)和联合索引(Composite Index)的核心差异在于索引结构与数据存储的关系。它们的存在会直接影响查询语句的执行路径、数据定位效率以及是否需要额外的“回表”操作。以下从索引特性、查询执行过程、关键差异三个维度展开分析:
一、前置知识:聚簇索引 vs 联合索引的本质区别
| 特性 | 聚簇索引 | 联合索引 |
|---|---|---|
| 定义 | 数据行的物理存储顺序与索引键顺序完全一致(索引即数据)。 | 由多个列组合而成的索引(非聚簇索引或聚簇索引的一种形式)。 |
| 数量限制 | 一张表仅有一个聚簇索引(通常是主键)。 | 一张表可创建多个联合索引(基于不同列组合)。 |
| 叶子节点内容 | 存储完整的数据行(如 InnoDB 的主键索引,叶子节点即数据页)。 | 若为非聚簇索引(如 MySQL 的二级索引),叶子节点存储聚簇索引键(如主键值); 若为聚簇索引(如复合主键),叶子节点存储数据行。 |
| 排序依据 | 按单个索引键的顺序物理排序(如主键 id 从小到大)。 | 按多个列的顺序分层排序(如 (a, b) 索引先按 a 排序,a 相同再按 b 排序)。 |
二、查询执行过程的具体差异
假设我们有一张订单表 orders,包含字段 id(主键,聚簇索引)、user_id、order_time、amount。
表结构示例:
CREATE TABLE orders (
id INT PRIMARY KEY, -- 聚簇索引(数据按 id 物理排序)
user_id INT,
order_time DATETIME,
amount DECIMAL(10,2),
INDEX idx_user_order (user_id, order_time) -- 联合索引(user_id + order_time)
);
场景 1:查询使用聚簇索引(如主键查询)
查询语句:SELECT * FROM orders WHERE id = 100;
执行过程:
- 索引查找:由于
id是聚簇索引,数据库直接通过聚簇索引树定位到id=100的叶子节点。 - 获取数据:聚簇索引的叶子节点直接存储完整数据行,因此无需额外操作,直接返回该行数据。
关键特点:
- 仅需一次索引查找,无回表(数据与索引一体)。
- 执行效率极高(O(log n) 时间复杂度)。
场景 2:查询使用联合索引(非聚簇索引)
查询语句:SELECT * FROM orders WHERE user_id = 5 AND order_time > '2023-01-01';
执行过程:
- 联合索引查找:联合索引
idx_user_order按(user_id, order_time)分层排序,数据库通过索引树快速定位到user_id=5且order_time > '2023-01-01'的所有索引条目。每个索引条目存储的是(user_id, order_time, id)(联合索引列 + 聚簇索引键id)。 - 回表查询(Bookmark Lookup):由于联合索引是非聚簇索引,叶子节点不存储完整数据行,仅存储聚簇索引键
id。数据库需要根据每个id值,回到聚簇索引树中查找对应的数据行(即通过id再次定位到聚簇索引的叶子节点)。 - 返回结果:将所有数据行汇总后返回。
关键特点:
- 需两次索引查找(联合索引 → 聚簇索引),存在回表开销。
- 若查询仅需联合索引中的列(如
SELECT user_id, order_time),则无需回表(覆盖索引)。
场景 3:查询使用联合索引作为覆盖索引
查询语句:SELECT user_id, order_time FROM orders WHERE user_id = 5;
执行过程:
- 联合索引查找:通过
idx_user_order索引树定位到user_id=5的所有索引条目。 - 直接返回数据:索引条目已包含
user_id和order_time(覆盖索引),无需回表。
关键特点:
- 仅需一次索引查找,无回表,效率接近聚簇索引查询。
三、核心差异总结
| 维度 | 使用聚簇索引的查询 | 使用联合索引的查询 |
|---|---|---|
| 索引与数据的关系 | 索引即数据(叶子节点存储完整数据行)。 | 非聚簇索引时,叶子节点存储聚簇索引键(需回表); 若为覆盖索引,无需回表。 |
| 回表操作 | 无(数据直接从索引获取)。 | 可能有(取决于是否覆盖索引)。 |
| 查询效率 | 最高(一次查找,无额外开销)。 | 取决于是否覆盖索引: – 覆盖索引:效率高(一次查找); – 非覆盖索引:需回表(两次查找)。 |
| 索引匹配规则 | 精确匹配索引键(如主键 id)。 | 需匹配最左前缀(如 (a,b) 索引支持 a、a+b 条件)。 |
| 数据排序 | 数据按索引键物理排序(范围查询更高效)。 | 数据不按联合索引排序(范围查询依赖索引分层结构)。 |
四、实战建议
- 优先利用覆盖索引:设计联合索引时,尽量让查询所需的列包含在索引中(如
SELECT col1, col2则索引包含(a, b, col1, col2)),避免回表。 - 聚簇索引选择:聚簇索引键应尽量短且稳定(如自增 id),避免随机写入导致页分裂。
- 联合索引最左前缀:查询条件需匹配联合索引的左前缀(如 (a,b,c) 索引支持 a、a+b、a+b+c 条件,但不支持单独 b 或 c)。
- 避免过度索引:联合索引可替代多个单列索引,减少维护成本。
总结:聚簇索引的查询直接定位数据,效率最高;联合索引的查询依赖是否覆盖索引,可能需回表。理解两者的执行差异,能帮助优化索引设计和查询语句,显著提升数据库性能。
流式处理
处理大量数据时,流式分批处理是避免内存溢出(OOM)、提升处理效率的核心手段。其本质是将大流切割成多个小批次(Batch),逐批处理,从而降低单批次的内存占用,同时保留流的声明式优势。
一、为什么需要流式分批?
直接处理大量数据(如百万级、千万级记录)时,若一次性加载到内存,会导致:
- 内存溢出:数据量超过JVM堆容量;
- 处理缓慢:单批次处理时间过长,占用资源;
- 垃圾回收压力:大量对象存活时间长,触发Full GC。
流式分批通过“小步快跑”的方式,将数据分成固定大小的批次,逐批加载、处理、释放内存,完美解决上述问题。
二、Java流式分批的核心方式
Java流式分批主要有两种思路:基于limit/skip的简单分批(适合小数据量)、基于自定义Spliterator的高效分批(适合大数据量)。
1. 基于limit/skip的简单分批(入门级)
利用Stream.limit(n)限制每批大小,Stream.skip(m)跳过已处理的记录,组合实现分批。
示例:将10万条数据分成每批1000条处理:
List<Data> bigData = ... // 假设是10万条数据的列表
int batchSize = 1000;
long total = bigData.size();
// 循环分批:从第0条开始,每次跳过i*batchSize条,取batchSize条
for (long i = 0; i < total; i += batchSize) {
List<Data> batch = bigData.stream()
.skip(i * batchSize) // 跳过已处理的记录
.limit(batchSize) // 取当前批次
.collect(Collectors.toList());
processBatch(batch); // 处理批次(如保存到数据库)
}
缺点:
skip()的时间复杂度是O(m)(m是跳过的记录数),当i很大时,skip()会遍历大量已跳过的元素,效率极低;- 不适合流式数据源(如
Files.lines、KafkaConsumer),因为这些数据源无法随机访问(不支持skip)。
2. 基于Spliterator的高效分批(推荐)
Spliterator(拆分迭代器)是流的底层数据拆分工具,可实现零拷贝、无跳过的分批。通过自定义Spliterator,将大流拆分成多个固定大小的子流(批次),逐批处理。
步骤1:实现BatchingSpliterator
自定义一个Spliterator,将原始流按批次拆分:
import java.util.*;
import java.util.function.Consumer;
import java.util.stream.Stream;
import java.util.stream.StreamSupport;
public class BatchingSpliterator<T> implements Spliterator<List<T>> {
private final Spliterator<T> sourceSpliterator;
private final int batchSize;
public BatchingSpliterator(Spliterator<T> sourceSpliterator, int batchSize) {
this.sourceSpliterator = sourceSpliterator;
this.batchSize = batchSize;
}
@Override
public boolean tryAdvance(Consumer<? super List<T>> action) {
List<T> batch = new ArrayList<>(batchSize);
// 尝试取batchSize个元素到批次
for (int i = 0; i < batchSize; i++) {
if (!sourceSpliterator.tryAdvance(batch::add)) {
break; // 没有更多元素,停止
}
}
if (batch.isEmpty()) {
return false; // 批次为空,结束
}
action.accept(batch); // 处理当前批次
return true;
}
@Override
public Spliterator<List<T>> trySplit() {
// 不支持并行拆分(若需并行,可调整此处逻辑)
return null;
}
@Override
public long estimateSize() {
// 估算剩余元素数量(可选)
return sourceSpliterator.estimateSize() / batchSize;
}
@Override
public int characteristics() {
return sourceSpliterator.characteristics();
}
// 工具方法:将流转换为批次流
public static <T> Stream<List<T>> batch(Stream<T> stream, int batchSize) {
return StreamSupport.stream(
new BatchingSpliterator<>(stream.spliterator(), batchSize),
false // 是否并行(false表示顺序流)
).onClose(stream::close); // 关闭时同步关闭原始流
}
}
步骤2:使用批次流处理大量数据
将原始流转换为批次流,逐批处理:
// 示例:处理10万条数据的流,每批1000条
Stream<Data> dataStream = ... // 原始流(如Files.lines、数据库游标流)
int batchSize = 1000;
BatchingSpliterator.batch(dataStream, batchSize)
.forEach(batch -> {
processBatch(batch); // 处理批次(如保存到数据库)
});
优势:
- 无
skip开销:直接按批次拆分,避免跳过大量元素; - 支持流式数据源:适用于
Files.lines、InputStream、数据库游标等无法随机访问的数据源; - 内存友好:每批仅加载固定数量的元素,处理完立即释放内存。
3. 并行流分批(进阶)
若数据量极大,可结合并行流提升处理速度,但需注意:
- 并行流的分批需保证线程安全(处理函数无状态);
- 自定义
Spliterator支持并行拆分(调整trySplit方法)。
示例:并行处理批次流
修改BatchingSpliterator的trySplit方法,支持并行拆分:
@Override
public Spliterator<List<T>> trySplit() {
// 拆分原始Spliterator为两部分,分别处理
Spliterator<T> split = sourceSpliterator.trySplit();
if (split == null) {
return null;
}
return new BatchingSpliterator<>(split, batchSize);
}
使用时,将流转换为并行流:
BatchingSpliterator.batch(dataStream.parallel(), batchSize)
.forEach(batch -> {
processBatch(batch); // 处理函数需无状态(避免线程安全问题)
});
三、结合数据库/文件的实际场景
场景1:数据库大量数据分批更新
用JPA的Stream结合批次处理,避免一次性加载所有数据:
@Autowired
private EntityManager entityManager;
public void batchUpdateUsers() {
String jpql = "SELECT u FROM User u WHERE u.status = :status";
Stream<User> userStream = entityManager.createQuery(jpql, User.class)
.setParameter("status", "PENDING")
.getResultStream(); // 返回流,不一次性加载所有数据
BatchingSpliterator.batch(userStream, 1000)
.forEach(batch -> {
batch.forEach(user -> user.setStatus("PROCESSED"));
entityManager.flush(); // 刷新当前批次
entityManager.clear(); // 清除持久化上下文,避免内存溢出
});
}
场景2:文件大量数据分批处理
用Files.lines读取文件流,分批处理:
Path filePath = Paths.get("large-file.csv");
try (Stream<String> lines = Files.lines(filePath, StandardCharsets.UTF_8)) {
BatchingSpliterator.batch(lines, 1000)
.forEach(batch -> {
// 解析每批CSV行,处理业务逻辑
List<Data> dataList = batch.stream()
.map(this::parseCsvLine)
.collect(Collectors.toList());
saveToDatabase(dataList);
});
} catch (IOException e) {
e.printStackTrace();
}
四、最佳实践
- 批次大小选择:内存充足:每批1000-10000条(根据对象大小调整);内存有限:每批100-500条(避免OOM);测试调整:通过JMeter或VisualVM监控内存使用,找到最优值。
- 避免副作用:处理函数需无状态(不修改外部变量),尤其是并行流场景;若需修改外部状态(如计数器),用
AtomicInteger等线程安全类。 - 及时释放资源:使用
try-with-resources关闭流(如Files.lines、EntityManager的流);处理完批次后,清除持久化上下文(如JPA的entityManager.clear()),避免内存泄漏。 - 优先用自定义
Spliterator:避免limit/skip的skip开销,尤其适合流式数据源;支持并行处理,提升效率。
总结
流式分批处理的核心是“拆分大流为小批次”,通过自定义Spliterator实现高效、无开销的分批,结合流的声明式风格,既能处理大量数据,又能保持代码简洁。关键要点:
- 避免
limit/skip的skip开销; - 支持流式数据源;
- 控制批次大小,保证内存安全;
- 线程安全(并行流场景)。
通过这种方式,可轻松处理百万级、千万级数据,同时保持系统的高可用性和性能。
在实时编辑场景下,tcp的网络丢包问题怎么解决,怎么保障用户的体验
用户痛点
- 延迟敏感
- 数据一致性
- 高可靠性
主要策略
传输层优化
TCP参数调整
关闭Nagle算法:Nagle 算法会缓存小包(如键盘输入的单个字符),合并后发送,导致延迟增加。实时编辑需关闭此算法,让小包立即发送。
优化RTO(超时重传时间):默认 RTO 是动态计算的,但在实时场景下可适当缩短(如从 3s 缩至 1s),减少重传等待时间,优化方案可以考虑前向纠错和BBR算法
启用SACK(选择性确认):TCP 的 SACK 允许接收方告知发送方“哪些包已收到,哪些未收到”,发送方只需重传丢失的包,而非整个窗口,减少重传数据量。
更换拥塞控制算法
传统 TCP 拥塞控制(如 CUBIC)在高丢包场景下会大幅降低吞吐量,加剧延迟。推荐使用BBR 算法(Bottleneck Bandwidth and RTT):
- BBR 不依赖丢包判断拥塞,而是通过测量网络的瓶颈带宽和最小 RTT 调整发送速率,更适合实时场景(如 Google Docs 已采用)。
- 效果:减少因误判拥塞导致的速率下降,降低丢包率。
使用QUIC协议代替TCP
QUIC(Quick UDP Internet Connections)是基于 UDP 的新一代传输协议,集成了 TCP 的可靠性与 UDP 的低延迟,完美适配实时编辑:
- 内置 FEC(前向纠错):发送方额外发送冗余包(如每 10 个数据包发 2 个 FEC 包),接收方可通过 FEC 恢复丢失的包,无需等待重传。
- 快速重传:通过 ACK 序列号快速检测丢包,无需等待 RTO。
- 连接迁移:基于 Connection ID,切换网络(如 Wi-Fi → 4G)时不中断连接,避免重连延迟。
- 应用层支持:Chrome、Edge 等浏览器已原生支持 QUIC,适合 Web 端实时编辑。
应用层优化
(1) 增量同步而非全量同步
实时编辑的核心是同步操作而非数据。例如:
- 文档编辑:同步“插入字符 at 位置 X”“删除字符 at 位置 Y”等操作指令(Operation),而非整个文档内容。
- 效果:每个操作的体积远小于全量数据,即使丢包,重传/恢复的成本极低。
(2) 应用层 FEC(前向纠错)
在增量操作的基础上,应用层可额外添加 FEC 冗余:
- 例如:每发送 10 个操作指令,额外发送 2 个 FEC 指令(包含前 10 个操作的校验信息)。
- 接收方:若丢失 1-2 个操作,可通过 FEC 指令恢复,无需等待 TCP 重传。
- 优势:延迟极低(FEC 恢复是本地计算,无需网络请求),适合实时场景。
(3) 应用层 ACK 与快速重传
在增量同步的基础上,应用层可实现自定义的 ACK 机制:
- 接收方收到操作后,立即发送带序列号的 ACK。
- 发送方:若连续 2 个 ACK 未收到(如序列号 10、11 未 ACK),立即重传丢失的操作,无需等待 TCP 重传。
- 效果:重传延迟从 RTO(秒级)降至毫秒级,几乎无感知。
数据一致性保障
(1) 操作转换(Operational Transformation, OT)
- 原理:每个操作(如插入、删除)都有版本号,接收方收到操作后,根据版本号调整操作的顺序(转换),确保所有客户端的状态一致。
- 例子:客户端 A 在版本 5 插入字符“X”,客户端 B 在版本 5 删除字符“Y”,OT 会将两个操作转换为兼容的顺序,避免冲突。
- 应用:Google Docs 早期采用 OT,适合文本编辑。
(2) 冲突-free 复制数据类型(CRDT)
- 原理:每个客户端维护自己的状态,操作是幂等的(多次执行结果一致),即使丢包或乱序,最终状态也会收敛到一致。
- 例子:Figma 用 CRDT 同步绘图操作,每个形状的位置、颜色都是独立的,即使丢包,后续收到缺失的操作也能正确合并。
- 优势:无需中心服务器协调,离线也能编辑,恢复后自动一致,更适合分布式实时编辑。
用户体验补偿
(1) 加载占位符与平滑过渡
- 当丢包导致数据延迟时,显示骨架屏或缓存内容(如之前的编辑状态),避免空白。
- 数据到达后,用动画过渡(如渐变、滑动)替换直接刷新,减少视觉冲击。
(2) 操作预测与预渲染
- 根据用户的历史操作习惯,预测下一步操作(如输入“abc”后预测“d”),先显示预测内容,等真实数据到达后修正。
- 例子:用户在输入文字时,即使丢了一个字符,预测下一个字符并显示,用户几乎无感知。
(3) 错误提示与重试策略
- 若丢包率极高(如超过 20%),显示友好的错误提示(如“网络不佳,正在尝试恢复”),并自动切换到更可靠的传输方式(如从 QUIC 切回 TCP)。
- 重试策略:采用指数退避(Exponential Backoff),避免频繁重试加剧网络拥塞。
在数据库视角,如何确定方法瓶颈在IO还是在CPU
CPU和IO瓶颈的典型特征
| 指标类别 | CPU 瓶颈特征 | IO 瓶颈特征 |
|---|---|---|
| CPU 使用率 | 整体 CPU 使用率高(>80%),尤其是用户态(us)。 | CPU 使用率低(<50%),但 wa(I/O 等待)占比高(>30%)。 |
| IO 等待时间 | wa低(<10%),CPU 空闲但响应慢。 | wa高(>30%),进程因等待磁盘 IO 而阻塞。 |
| 磁盘 IO 吞吐量 | 磁盘读写量低(如 < 100MB/s),但响应慢。 | 磁盘读写量高(如 > 500MB/s),队列积压(avgqu-sz高)。 |
| 内存使用 | 缓冲池(如 InnoDB Buffer Pool)命中率高(>99%),但 CPU 仍高。 | 缓冲池命中率低(<95%),频繁从磁盘加载数据。 |
| 锁与等待 | 锁等待少,但 CPU 忙于计算(如排序、聚合)。 | 锁等待可能伴随 IO 等待(如写日志、刷脏页)。 |
定位瓶颈的具体方法
1. 监控数据库核心指标
通过数据库自带工具或第三方监控平台,采集关键指标并分析。
(1) MySQL/InnoDB 场景
SHOW GLOBAL STATUS:关注以下指标:Threads_running:高值(> CPU 核数)可能表示 CPU 竞争激烈。Innodb_buffer_pool_reads:高值(> 1000/秒)表示缓冲池未命中,需从磁盘读取(IO 瓶颈)。Innodb_os_log_written:高值(> 10MB/秒)表示事务日志写入频繁(IO 瓶颈)。Created_tmp_disk_tables:高值(> 100/秒)表示临时表写入磁盘(IO 瓶颈)。SHOW ENGINE INNODB STATUS:查看SEMAPHORES部分的OS WAIT统计,若File I/O等待高,说明 IO 瓶颈。- 性能模式(Performance Schema):分析
events_statements_summary_by_digest,统计高耗时 SQL 的ROWS_EXAMINED(扫描行数)和CREATED_TMP_DISK_TABLES(磁盘临时表),判断是否因全表扫描或临时表导致 IO 高。
(2) PostgreSQL 场景
pg_stat_activity:查看state列,若大量进程处于idle in transaction或waiting for disk I/O,说明 IO 瓶颈。pg_stat_statements:分析total_time(总耗时)和shared_blks_read(共享块读取次数),若shared_blks_read高且total_time长,可能是 IO 瓶颈。pg_stat_database:关注blks_read(磁盘块读取)和blks_hit(缓冲池命中),若blks_read / (blks_read + blks_hit)> 10%,说明缓冲池未命中率高(IO 瓶颈)。
2. 分析 SQL 执行计划
通过执行计划判断 SQL 是计算密集型(CPU 瓶颈)还是IO 密集型(IO 瓶颈)。
(1) CPU 瓶颈的典型执行计划特征
- 全表扫描(ALL):无索引可用,需扫描全表数据(数据量大时 CPU 需处理大量行)。
- 排序(Using filesort):需在内存或磁盘排序(数据量大时 CPU 或 IO 均可能高,若内存不足则转为 IO)。
- 聚合(Using temporary):需创建临时表聚合数据(如
GROUP BY、DISTINCT,内存不足时写入磁盘)。 - 复杂计算:如
JSON_EXTRACT、REGEXP等函数,CPU 计算量大。
示例:
EXPLAIN SELECT * FROM orders WHERE create_time > '2023-01-01' ORDER BY amount DESC;
-- 执行计划显示:type=ALL(全表扫描),Extra=Using filesort(需要排序)
-- 结论:CPU 需处理全表扫描和排序,可能成为瓶颈。
(2) IO 瓶颈的典型执行计划特征
- 索引扫描(index):虽走索引,但索引未覆盖查询列(需回表查主键索引,增加 IO)。
- 随机 I/O:通过二级索引查询,需多次随机读取数据页(磁盘随机 IO 高)。
- 临时表写入磁盘:执行计划中
Extra=Using temporary; Using filesort,且created_tmp_disk_tables高。
示例:
EXPLAIN SELECT user_id, SUM(amount) FROM orders GROUP BY user_id;
-- 执行计划显示:type=index(索引扫描),Extra=Using temporary; Using filesort
-- 结论:需扫描索引并聚合,若内存不足,临时表写入磁盘(IO 瓶颈)。
3. 观察数据库进程状态
通过 SHOW PROCESSLIST(MySQL)或 pg_stat_activity(PostgreSQL)查看活跃进程的行为:
- CPU 密集型进程:进程状态为
Sending data、Sorting result、Copying to tmp table,且Time列较长(如 > 10s)。 - IO 密集型进程:进程状态为
Waiting for table metadata lock(可能因磁盘 IO 慢导致元数据加载延迟)、Waiting for disk I/O(明确等待磁盘)。
4. 压测验证瓶颈
通过压测工具(如 sysbench、pgbench)模拟负载,观察指标变化:
- CPU 瓶颈验证:增加并发连接数,若 CPU 使用率线性上升,但吞吐量(QPS)不再增长,说明 CPU 已饱和。
- IO 瓶颈验证:增加并发连接数,若磁盘 IO 吞吐量(如
iostat的%util> 80%)或队列(avgqu-sz> 5)显著升高,而 QPS 增长停滞,说明 IO 已饱和。
常见场景的瓶颈定位
场景 1:OLTP 短查询响应慢
- 现象:单条 SQL 执行快(< 10ms),但高并发时整体响应变慢。
- 分析:若 CPU 使用率高(>80%)且
wa低:可能是锁竞争(如行锁、表锁)或 CPU 计算(如触发器、存储过程)。若wa高(>30%)且磁盘 IO 高:可能是缓冲池命中率低(如频繁访问未缓存的热数据)。
场景 2:OLAP 大查询超时
- 现象:复杂查询(如多表 JOIN、聚合)执行时间长(> 10s)。
- 分析:若执行计划显示全表扫描或大量排序:CPU 需处理大量数据,可能成为瓶颈。若执行计划显示随机 I/O 或临时表写入磁盘:IO 成为瓶颈(如磁盘速度慢或容量不足)。
场景 3:写入操作慢
- 现象:INSERT/UPDATE 频繁时响应慢。
- 分析:若 CPU 使用率高:可能是事务提交时计算(如生成唯一键、触发器)。若
wa高且Innodb_os_log_written高:可能是事务日志写入磁盘慢(如机械盘 vs SSD)。
AOF详解
AOF(Append Only File,追加日志文件)是 Redis 提供的持久化机制之一,核心原理是通过记录所有写操作命令到文件中,实现数据的持久化。当 Redis 重启时,通过重新执行 AOF 文件中的命令,恢复数据到内存。
一、AOF 的核心原理
AOF 持久化的本质是“日志回放”:
- 记录写命令:Redis 执行的每一个写操作(如
SET、DEL、HSET),都会被追加到 AOF 文件中(使用 Redis 协议格式,可读性强)。 - 重启恢复:Redis 重启时,读取 AOF 文件,按顺序执行所有写命令,重建内存数据。
二、AOF 的关键特性
1. 命令追加(Append)
- 所有写命令以 Redis 协议格式(如
*3\r3\nSET˚\n˚1\rk\r$1\rv\r)追加到 AOF 文件末尾,保证文件的可读性和可修复性。 - 仅记录写操作,读操作(如
GET)不记录,减少文件体积。
- 同步策略(AppendFSync)
AOF 文件的同步(刷盘)策略决定了数据安全性和性能的平衡,通过 appendfsync参数配置:
| 策略 | 说明 | 数据安全性 | 性能影响 |
|---|---|---|---|
always | 每个写命令执行后,同步刷盘(调用 fsync())。 | 最高(最多丢失 1 条命令) | 性能最差(频繁刷盘) |
everysec(默认) | 每秒同步刷盘 1 次(后台线程执行)。 | 较高(最多丢失 1 秒内的命令) | 性能较好(折中方案) |
no | 由操作系统决定刷盘时机(通常每 30s 一次)。 | 最低(可能丢失较多命令) | 性能最好(无额外开销) |
- AOF 重写(Rewrite)
随着写操作增多,AOF 文件会不断增大(可能达到 GB 级别)。重写机制通过压缩冗余命令,生成更小的 AOF 文件:
- 触发条件(需同时满足):AOF 文件大小超过
auto-aof-rewrite-min-size(默认 64MB);AOF 文件大小比上次重写后增长超过auto-aof-rewrite-percentage(默认 100%,即翻倍)。 - 重写过程:主进程创建子进程(
fork());子进程读取当前内存数据,生成新的 AOF 文件(仅包含重建数据的最小命令集);主进程继续处理写请求,将新命令追加到旧 AOF 文件和新 AOF 文件;子进程完成重写后,主进程将旧文件重命名,新文件替换为当前 AOF 文件。
三、AOF 的优缺点
优点
- 数据安全性高:通过
appendfsync策略,可配置最多丢失 1 秒或更少的命令。 - 可读性强:AOF 文件是明文的 Redis 协议,可直接查看或手动修复(如删除错误命令)。
- 支持增量持久化:仅记录写操作,文件增长较 RDB(快照)更平缓。
缺点
- 文件体积大:相比 RDB(二进制快照),AOF 文件通常更大(包含所有写命令)。
- 恢复速度慢:重启时需逐条执行命令,耗时比 RDB 长(尤其数据量大时)。
- 写性能影响:
always策略会显著降低写性能(频繁刷盘);everysec策略仍有后台刷盘开销。
四、AOF 与 RDB 的对比
| 维度 | AOF | RDB |
|---|---|---|
| 持久化方式 | 记录写命令(日志) | 定期生成内存快照(二进制) |
| 数据安全性 | 高(可配置丢失 1 秒内命令) | 低(取决于快照间隔,可能丢失最后一次快照后的数据) |
| 文件体积 | 较大(包含所有写命令) | 较小(二进制压缩快照) |
| 恢复速度 | 慢(需逐条执行命令) | 快(直接加载内存快照) |
| 适用场景 | 对数据安全性要求高的场景(如金融、交易) | 对性能要求高、允许少量数据丢失的场景 |
五、AOF 的配置与实践
1. 启用 AOF
在 redis.conf中配置:
appendonly yes # 启用 AOF
appendfilename "appendonly.aof" # AOF 文件名
2. 配置同步策略
appendfsync everysec # 默认每秒刷盘(推荐)
# appendfsync always # 高安全性场景(如支付系统)
# appendfsync no # 性能优先场景(如日志缓存)
3. 配置重写参数
auto-aof-rewrite-min-size 64mb # 最小重写文件大小(默认 64MB)
auto-aof-rewrite-percentage 100 # 文件增长百分比阈值(默认 100%)
4. 手动触发重写
通过命令手动触发 AOF 重写(无需等待自动触发):
redis-cli bgrewriteaof # 后台执行重写
5. 修复损坏的 AOF 文件
若 AOF 文件因意外损坏(如磁盘故障),可通过 redis-check-aof工具修复:
redis-check-aof --fix appendonly.aof # 修复 AOF 文件
六、AOF 的适用场景
- 高数据安全性要求:如金融交易、用户账户系统,需保证数据几乎不丢失。
- 写操作频繁但数据量不大:AOF 的写开销可接受(如缓存系统、计数器)。
- 需要增量恢复:误删数据时,可通过 AOF 文件回滚到某个时间点(需结合日志分析)。