KMP一次搞懂
求next数组
/**
* 获取一个字符串 pattern 的部分匹配表
*
* @param patternStr 用于模式匹配字符串
* @return 存储部分匹配表的每个子串的最长公共前后缀的 next数组
*/
public static int[] kmpNext(String patternStr) {
//将 patternStr 转为 字符数组形式
char[] patternArr = patternStr.toCharArray();
//预先创建一个next数组,用于存储部分匹配表的每个子串的最长公共前后缀
int[] next = new int[patternStr.length()];
/*
从第一个字符(对应索引为0)开始的子串,如果子串的长度为1,那么肯定最长公共前后缀为0
因为这唯一的一个字符既是第一个字符,又是最后一个字符,所以前后缀都不存在 -> 最长公共前后缀为0
*/
next[0] = 0;
/*
len有两个作用:
1. 用于记录当前子串的最长公共前后缀长度
2. 同时知道当前子串的最长公共前后缀的前缀字符串对应索引 [0,len-1]/当前子串最长公共前缀字符串的下一个字符的索引 <-- 可以拿示例分析一下
*/
int len = 0;
//从第二个字符开始遍历,求索引在 [0,i] 的子串的最长公共前后缀长度
int i = 1;
while (i < patternArr.length) {
/*
1.已经知道了上一个子串 对应索引[0,i-1] 的最长公共前后缀长度为 len
的前缀字符串是 索引[0,len-1],对应相等的后缀字符串是 索引[i-len,i-1]
2.因此我们可以以 上一个子串的最长公共前后缀字符串 作为拼接参考
比较一下 patternArr[len] 与 patternArr[i] 是否相等
*/
if (patternArr[len] == patternArr[i]) {
/*
1.如果相等即 patternArr[len]==patternArr[i],
那么就可以确定当前子串的最长公共前后缀的
前缀字符串是 索引[0,len] ,对应相等的后缀字符串是 索引[i-len,i]
2.由于是拼接操作,那么当前子串的最长公共前后缀长度只需要在上一个子串的最长公共前后缀长度的基础上 +1 即可
即 next[i] = next[i-1] + 1 ,
3.由于 len 是记录的子串的最长公共前后缀长度,对于当前我们所在的代码位置而言
len 还是记录的上一个子串的最长公共前后缀长度,因此:
next[i] = next[i-1] + 1 等价于 next[i] = ++len
*/
// 等价于 next[i] = next[i-1] + 1
next[i] = ++len;
//既然找到了索引在[0,i]的子串的最长公共前后缀字符串长度,那就 i+1 去判断以下一个字符结尾的子串的最长公共前后缀长度
i++;
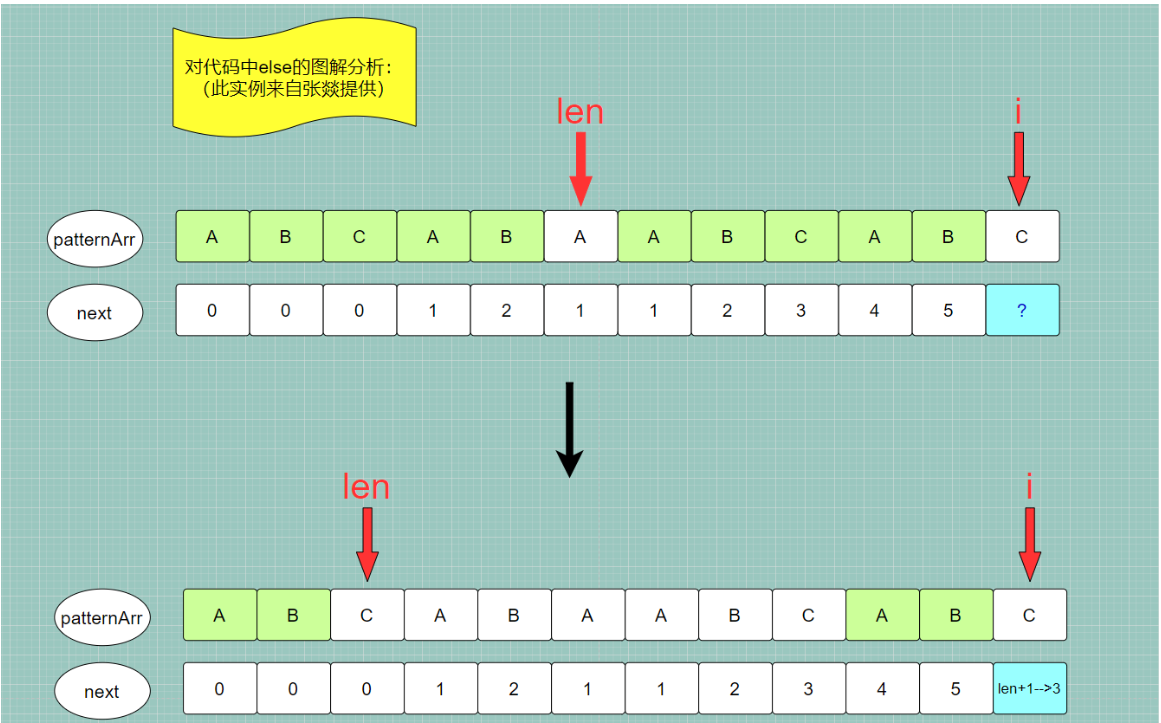
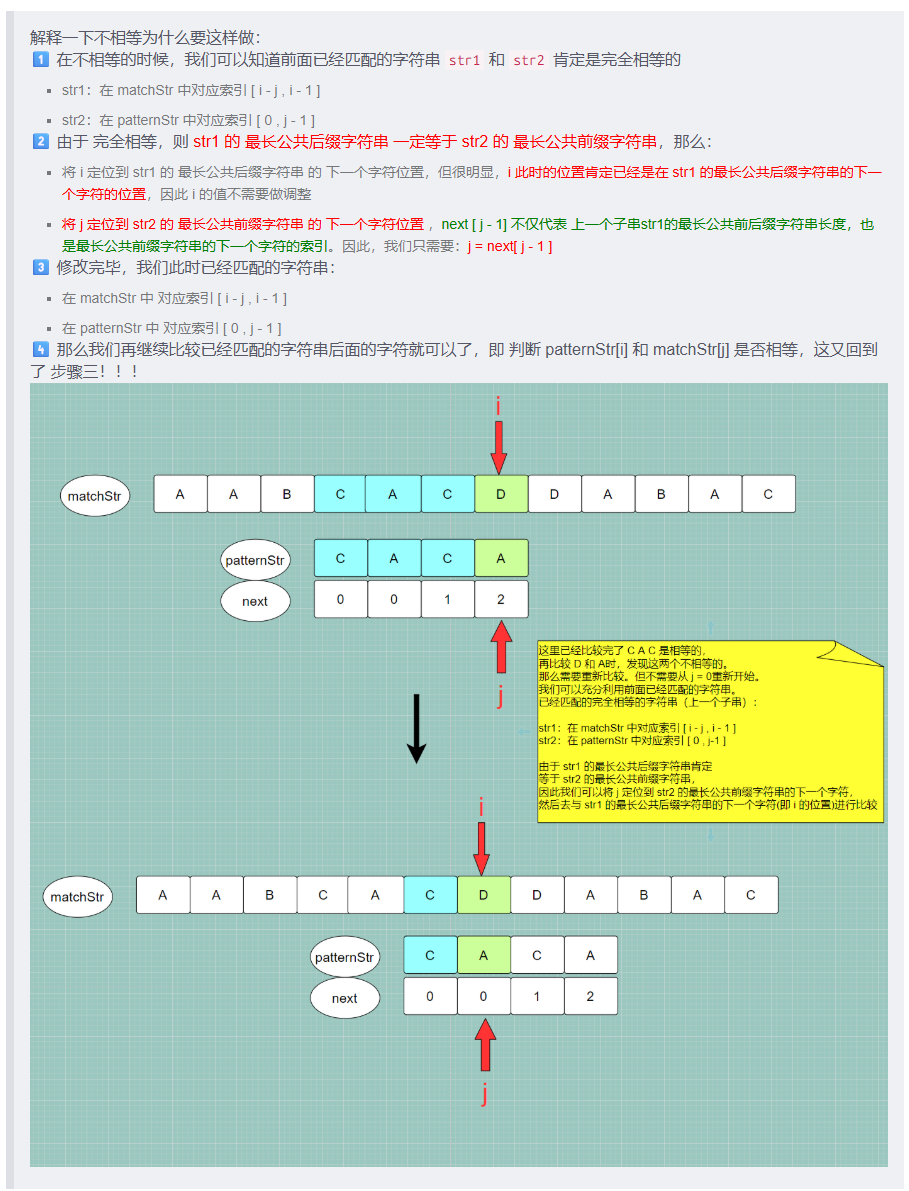
}else {
/*
1.如果不相等 patternArr[len]!=patternArr[i]
我们想要求当前子串 对应索引[0,i] 的最长公共前后缀长度
我们就不能以 上一个子串的最长公共前后缀:前缀字符串pre 后缀字符串post (毫无疑问pre==post) 作为拼接参考
2.但可以思考一下:
pre的最长公共前缀字符串: 索引 [ 0 , next[len-1] )
是等于
post的最长公共后缀字符串:索引 [ i-next[len-1] , i )
则我们 就以 pre的最长公共前缀字符串/post的最长公共后缀字符串 作为拼接参考
去判断 pre的最长公共前缀字符串的下一个字符patternArr[next[len-1]] 是否等于 post的最长公共后缀字符串的下一个字符patternArr[i]
3.在第 1,2 步分析的基础上
我们可以在判断出 patternArr[len]!=patternArr[i] 后,
不去执行第二步:patternArr[next[len-1]] 是否等于 patternArr[i],
可以先修改len的值:len = next[len-1],len就成了 pre的最长公共前缀字符串长度/post的最长公共后缀字符串长度,
修改完之后,再去判断下一个字符 是否相等,即 判断 patternArr[len] 是否等于 patternArr[i]
仔细观察,这不又是在判断 这个循环中 if-else 语句吗
4.关于 len 这个值,在循环开始时我们解释的是:上一个子串的最长公共前后缀字符串的长度
但实际上我们在这里改为 len = next[len-1] 表示上一个子串的最长公共前后缀字符串的最长公共前后缀字符串的长度
是没有问题的,等价于上一个子串的较小的公共前后缀字符串。
既然进入了 else 语句说明字符不相等,就不能以 上一个子串的最长公共前后缀字符串 作为 拼接参考,就应当去缩小参考范围。
*/
if(len==0) {
/*
len为0说明上一个子串已经没有了公共前后缀字符串
则我们没有继续寻找的必要 --> 索引在[0, i]的当前子串的最长公共前后缀字符串长度就是0
*/
next[i] = len;
//继续寻找下一个字符串的最长公共前后缀字符串长度
i++;
}else{
len = next[len - 1];
}
}
}
return next;
}
自行实现
配图好理解
package org.example;
import java.util.ArrayList;
import java.util.List;
public class Kmp {
public int[] getNext(String pattern) {
char[] chars = pattern.toCharArray();
int[] next = new int[chars.length];
next[0] = 0;
int len = 0;
int i = 1;
while (i < chars.length) {
//如果你的新字符串的最后一个字符和前一个字符串的最大公共前缀的后一个字符相同,那你的新字符串的next值就可以以前一个做参考
if (chars[i] == chars[len]) {
next[i] = len++;
i++;
} else {
//当不满足上述情况的时候,需要和前一个字符的最长公共前缀的后一个字符比较,因为你前一个字符有公共前后缀的话,前缀和后缀相同,要通过这个更快找到最大前后缀
if (len == 0)
next[i] = 0;
else {
len = next[len - 1];
}
}
}
return next;
}
//匹配到一个就OK
public int KmpSearchOne(String matchStr, String patternStr, int next[]) {
int i = 0, j = 0;
while (i < matchStr.length() && j < patternStr.length()) {
if (matchStr.charAt(i) == patternStr.charAt(j)) {
i++;
j++;
} else {
if (j == 0)
i++;
else
j = next[j - 1];
}
}
return j == patternStr.length() ? i - j : -1;
}
//可匹配多个,允许有多个重复字符串
public List<Integer> KmpSearchAllSame(String matchStr, String patternStr, int next[]) {
List<Integer> list = new ArrayList<>();
int i = 0, j = 0;
while (i < matchStr.length() && j < patternStr.length()) {
if (matchStr.charAt(i) == patternStr.charAt(j)) {
i++;
j++;
} else {
if (j == 0)
i++;
else
j = next[j - 1];
}
if (j == patternStr.length()) {
list.add(i - j);
j = next[j - 1];
}
}
return list;
}
//匹配多个,不允许有重复字符串
public List<Integer> KmpSerchAllNoSame(String matchStr, String patternStr, int next[]) {
List<Integer> list = new ArrayList<>();
int i = 0, j = 0;
while (i < matchStr.length() && j < patternStr.length()) {
if (matchStr.charAt(i) == patternStr.charAt(j)) {
i++;
j++;
} else {
if (j == 0)
i++;
else
j = next[j - 1];
}
}
if (j == patternStr.length()) {
list.add(i - j);
j = 0;
}
return list;
}
}
八大排序算法
package org.example;
public class Sort {
//插入排序
//在不断向后遍历的过程中,将当前元素插入到前方已经排序的元素中
public void insertionSort(int[] arr) {
for (int i = 1; i < arr.length; i++) {
int val = arr[i];
int j = i;
while (j > 0 && arr[j - 1] > val) {
arr[j] = arr[j - 1];
j--;
}
arr[j] = val;
}
}
//冒泡排序
//两两比较,将最大的数冒泡到末尾
public void bubbleSort(int[] arr) {
for (int i = 0; i < arr.length - 1; i++) {
//用来标识是否进行过交换,没有交换则证明已经排序完毕
boolean flag = true;
//每次for循环会确定一个最大的元素,直至全部有序
for (int j = 0; j < arr.length - i - 1; j++) {
if (arr[j] > arr[j + 1]) {
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
flag = false;
}
}
if (flag) {
break;
}
}
}
//选择排序
//每次选择最小的元素,将其放到当前位置
public void selectionSort(int[] arr) {
int len = arr.length;
for (int i = 0; i < len; i++) {
int minval = i;
for (int j = minval + 1; j < len; j++) {
if (arr[j] < arr[minval]) {
minval = j;
}
}
if (minval != i) {
int temp = arr[i];
arr[i] = arr[minval];
arr[minval] = temp;
}
}
}
//希尔排序
//希尔排序是插入排序的改进版,它使用一个增量序列来控制插入排序的步长,
//然后对序列进行分组,对每组进行插入排序,最后再对整个序列进行插入排序。
public void shellSort(int[] arr) {
int len = arr.length;
for (int gap = len / 2; gap > 0; gap /= 2) {
for (int i = gap; i < len; i++) {
int tmep = arr[i];
int j = i - gap;
while (j >= 0 && arr[j] > tmep) {
arr[j + gap] = arr[j];
j -= gap;
}
arr[j + gap] = tmep;
}
}
}
//归并排序
public void mergeSort(int[] arr) {
if (arr.length <= 1)
return;
int mid = arr.length / 2;
int[] left = new int[mid];
int[] right = new int[arr.length - mid];
for (int i = 0; i < mid; i++) {
left[i] = arr[i];
}
for (int i = mid; i < arr.length; i++) {
right[i - mid] = arr[i];
}
mergeSort(left);
mergeSort(right);
arr = merge(left, right);
}
public int[] merge(int[] left, int[] right) {
int i = 0, j = 0, k = 0;
int result[] = new int[left.length + right.length];
while (i < left.length && j < right.length) {
if (left[i] < right[j]) {
result[k++] = left[i++];
} else {
result[k++] = right[j++];
}
}
while (i < left.length) {
result[k++] = left[i++];
}
while (j < right.length) {
result[k++] = right[j++];
}
return result;
}
//快速排序
//先决条件left=0,right=arr.length-1
public void quickSort(int[] arr, int left, int right) {
for (int i = 0; i < arr.length; i++) {
int base=arr[i];
while (left<right){
while (left<right&&arr[right]>=base){
right--;
}
arr[left]=arr[right];
while (left<right&&arr[left]<=base){
left++;
}
arr[right]=arr[left];
}
arr[left]=base;
quickSort(arr,0,left-1);
quickSort(arr,left+1,right);
}
}
//堆排序
//建堆
int []arr=new int[10];
//这里要做统一的管理,防止建堆把已经排序的重新建堆
int len=arr.length;
public void buildHeap(int[] arr,int index) {
int left = index * 2 + 1;
int right = index * 2 + 2;
int max = index;
if (left < len && arr[left] > arr[max]) {
max = left;
}
if (right < len && arr[right] > arr[max]) {
max = right;
}
if (max != index) {
int temp = arr[index];
arr[index] = arr[max];
arr[max] = temp;
buildHeap(arr, max);
}
}
public void heapSort(int[] arr) {
for (int i = arr.length; i >= 0; i--) {
buildHeap(arr, i);
}
for (int i = arr.length-1; i >=0 ; i--) {
swap(arr,0,len-1);
buildHeap(arr,i);
len--;
}
}
public void swap(int[] arr, int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
//计数排序
public void countSort(int[] arr) {
int max = arr[0];
int min = arr[0];
for (int i = 1; i < arr.length; i++) {
if (arr[i] > max) {
max = arr[i];
}
if (arr[i] < min) {
min = arr[i];
}
}
int[] countArr = new int[max - min + 1];
for (int val : arr) {
countArr[val - min]++;
}
for (int arrIdx = 0, countIdx = 0; countIdx < countArr.length; countIdx++) {
while (countArr[countIdx]-- > 0) {
arr[arrIdx++] = min + countIdx;
}
}
}
}